
Adaptation few-shot du modèle CLIP pour améliorer la classification d'images sur des catégories connues tout en préservant la généralisation zero-shot. Comparaison d'approches récentes (CoOp, CoCoOp) sur le dataset Oxford Flowers-102, avec implémentation, évaluation et propositions d'améliorations.
1. Préparation du Dataset
Nous avons utilisé le dataset Oxford Flowers-102, composé de 102 catégories de fleurs.
- Base classes : 51 premières classes (avec 10 images par classe pour l’entraînement few-shot)
- Novel classes : 51 dernières classes (jamais vues en entraînement)
Nous avons appliqué une séparation stricte entre classes vues et non vues, assurant une bonne généralisation et une évaluation équitable.

Figure 1 - Exemples d’images issues du dataset
2. Évaluation Zero-Shot avec CLIP
Avant toute adaptation, nous avons évalué les performances de CLIP en zero-shot en utilisant le prompt suivant :
prompts = [f"a photo of a {class_name}, a type of flower." for class_name in class_names]Cette évaluation établit une ligne de base pour mesurer l’impact des méthodes d’adaptation sur les classes vues et non vues.
| Ensemble | Précision (%) |
|---|---|
| Base | 71.33 |
| Novel | 78.26 |
3. Méthode CoOp : Context Optimization
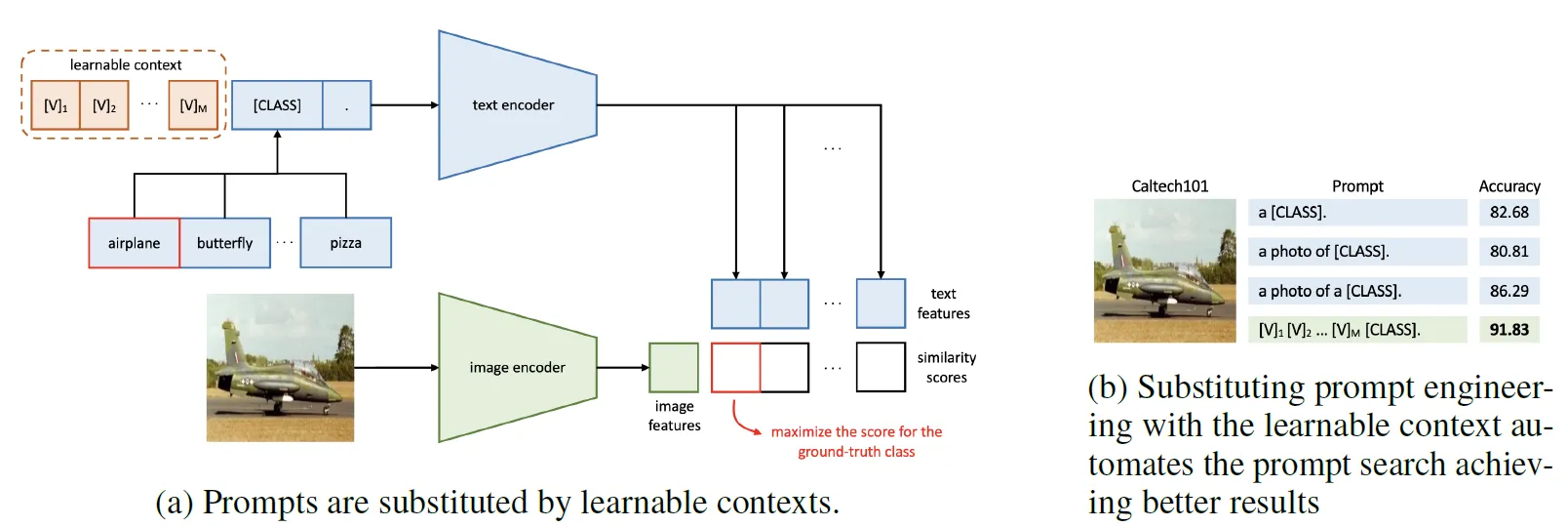
Figure 2 - CoOp Overview
L’approche CoOp remplace les prompts textuels statiques par des vecteurs de contexte apprenables, entraînés uniquement à partir des images d’entraînement few-shot. Le backbone CLIP reste gelé, ce qui réduit fortement le nombre de paramètres entraînés. En effet, nous avons pu constater que le fine-tuning mène majoritairement à de l’overfitting.
- Vecteurs de contexte : 16 tokens apprenables
- Structure du prompt :
[CTX_1] [CTX_2] ... [CTX_16] [CLASS]
class PromptLearner(nn.Module):
def __init__(...):
self.ctx = nn.Parameter(torch.empty(n_ctx, ctx_dim))
nn.init.normal_(self.ctx, std=0.02)Les résultats montrent une nette amélioration sur les classes de base mais une dégradation sur les classes novel due à l’overfitting :
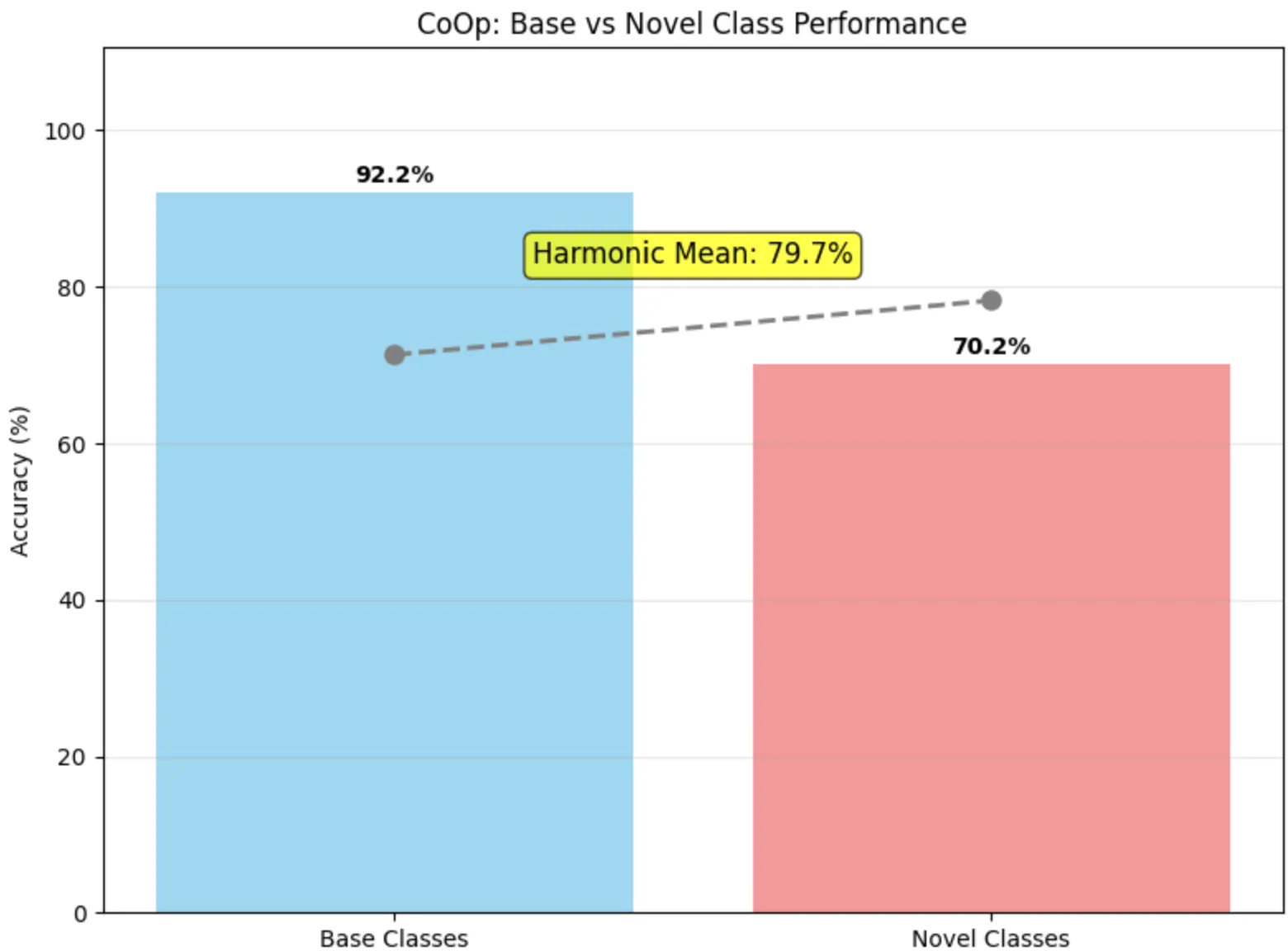
Figure 3 - Résultats CoOp
4. Amélioration de CoOp : Bruit Gaussien
Pour pallier la sur-spécialisation, nous avons introduit du bruit gaussien contrôlé pendant l’apprentissage des vecteurs de contexte. Cette régularisation permet d’améliorer la robustesse et la généralisation :
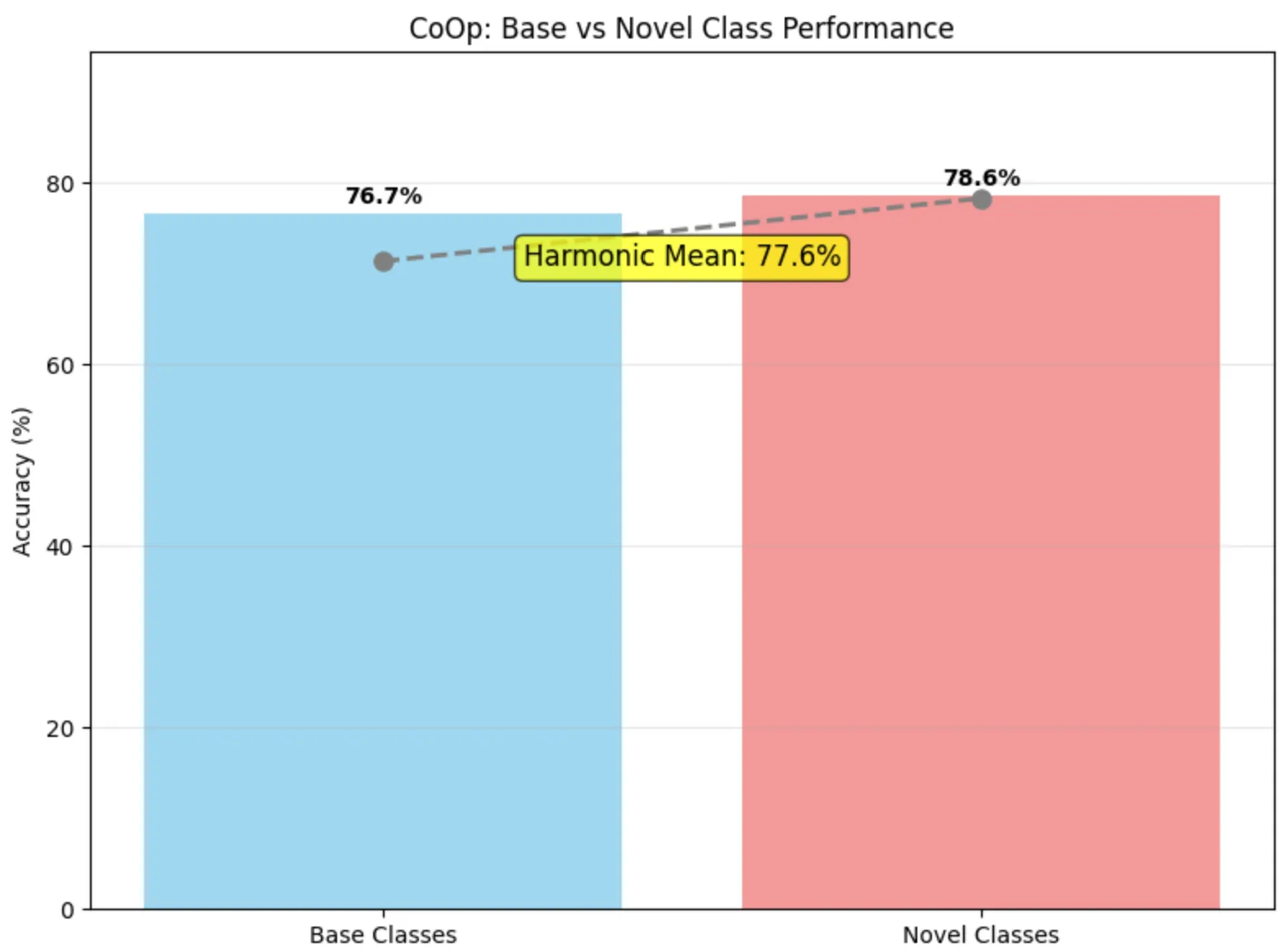
Figure 4 - Résultats CoOp avec bruit gaussien
| Modèle | Base (%) | Novel (%) | Moyenne harmonique |
|---|---|---|---|
| CoOp brut | 92.16 | 70.20 | 79.69 |
| CoOp + bruit | 76.67 | 78.63 | 77.63 |
if self.training and self.noise_scale:
noise = torch.randn_like(ctx) * (self.noise_scale * max_val)
ctx = ctx + noise5. Méthode CoCoOp : Context Conditionnel
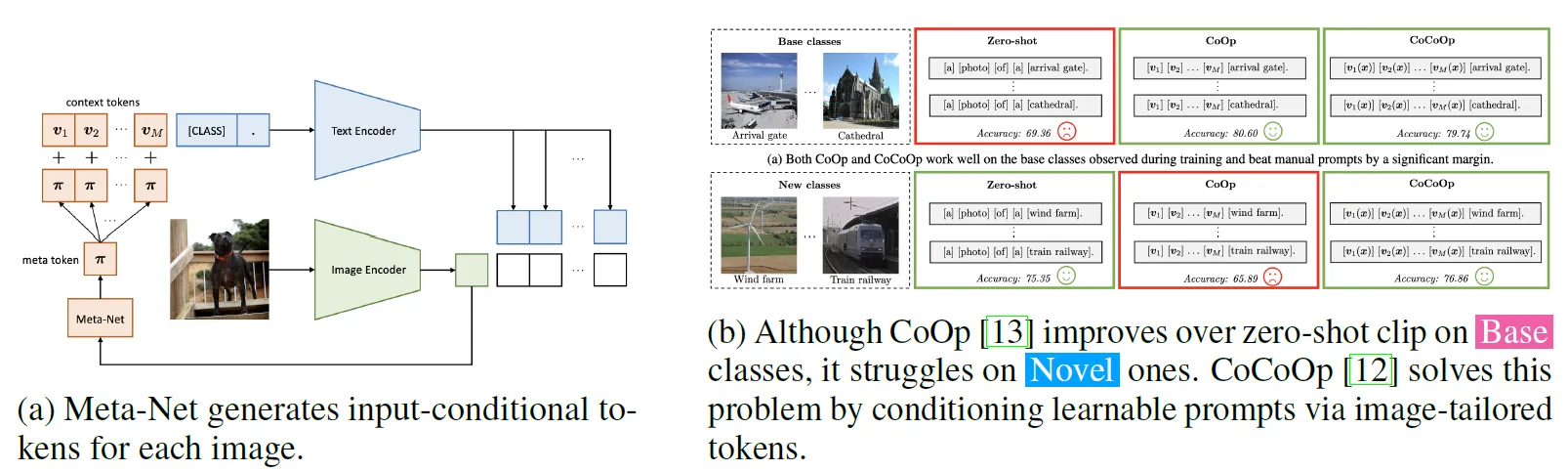
Figure 5 - CoCoOp Overview
Nous avons ensuite implémenté CoCoOp, qui améliore CoOp en rendant les vecteurs de contexte dépendants de l’image via un Meta-Net, un réseau léger conditionnant les prompts sur les caractéristiques visuelles.
- Base contextuel : Vecteurs fixes comme dans CoOp
- Meta-Net : Réseau qui génère un biais conditionnel sur chaque image avec une couche cachée qui réduit la taille d’input d’un facteur 16 :
ctx_shifted = ctx + self.meta_net(image_features)Cette méthode permet d’obtenir une meilleure généralisation aux classes novel tout en conservant des performances élevées sur les classes base :
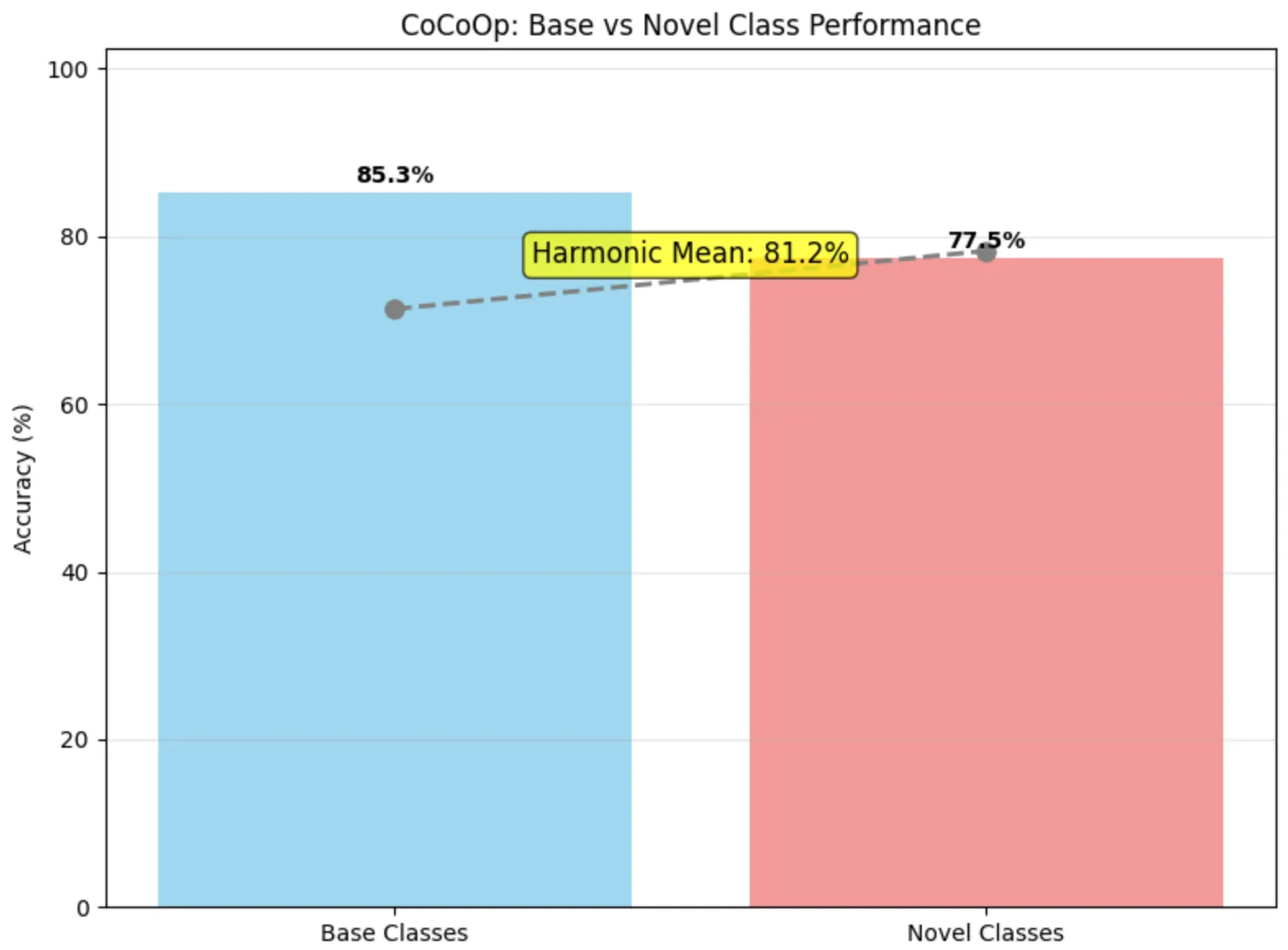
Figure 6 - Résultats CoCoOp
6. Améliorations de CoCoOp
Nous avons renforcé la capacité de généralisation de CoCoOp en modifiant l’architecture du Meta-Net et en gardant l’idée d’ajouter un bruit gaussien durant l’entraînement :
- Ajout de BatchNorm et Dropout
- Remplacement de certaines activations
- Test de différentes tailles de couches
self.meta_net = nn.Sequential(
nn.Linear(input_dim, hidden),
nn.BatchNorm1d(hidden),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden, ctx_dim)
)Ces ajustements ont permis de gagner en robustesse sans trop augmenter le coût d’entraînement :
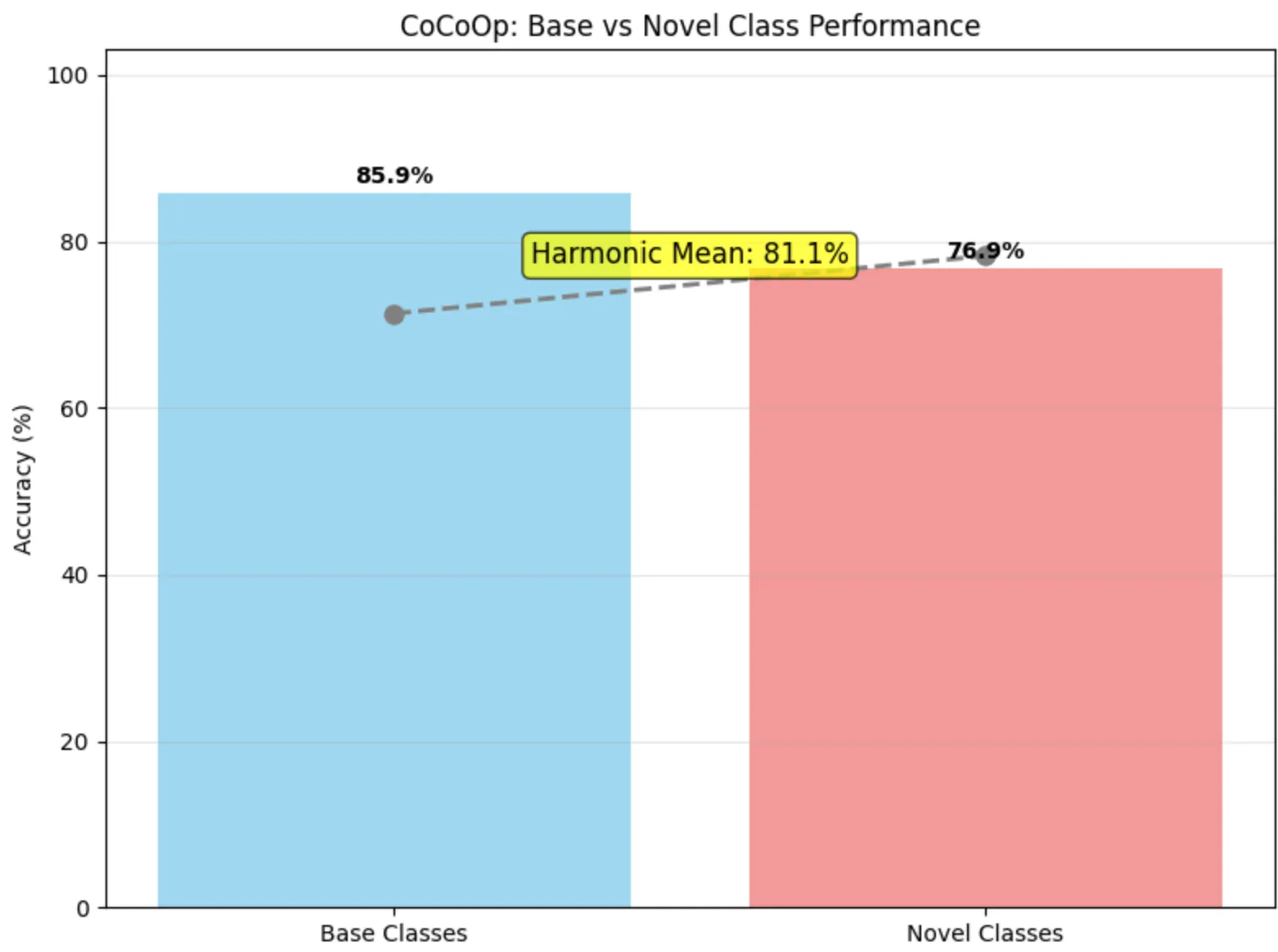
7. Amélioration de Meta-Net
Après avoir entraîné le modèle avec la méthode CoCoOp, nous avons exploré l’idée d’améliorer les images via un prétraitement afin d’aider le réseau à générer des tokens conditionnels plus discriminants. L’hypothèse de départ est qu’une amélioration des caractéristiques visuelles (comme une saturation plus marquée) pourrait renforcer le regroupement intra-classe (fleurs similaires proches) et la séparation inter-classe (fleurs différentes éloignées), améliorant ainsi les performances globales.
Pour cela, nous avons appliqué une amplification adaptative de contraste, motivée par des critères biologiques : les fleurs se distinguent souvent par leurs motifs et couleurs. Nous avons ensuite extrait les tokens conditionnels générés par le Meta-Net sur les versions brutes et modifiées des images, et comparé plusieurs métriques de clustering :
- Intra-class compactness
- Inter-class separation
- Discriminability ratio
- Adjusted Rand Index (ARI)
- Silhouette score
- Cluster purity
Nous avons également utilisé la méthode UMAP pour visualiser la distribution des tokens.
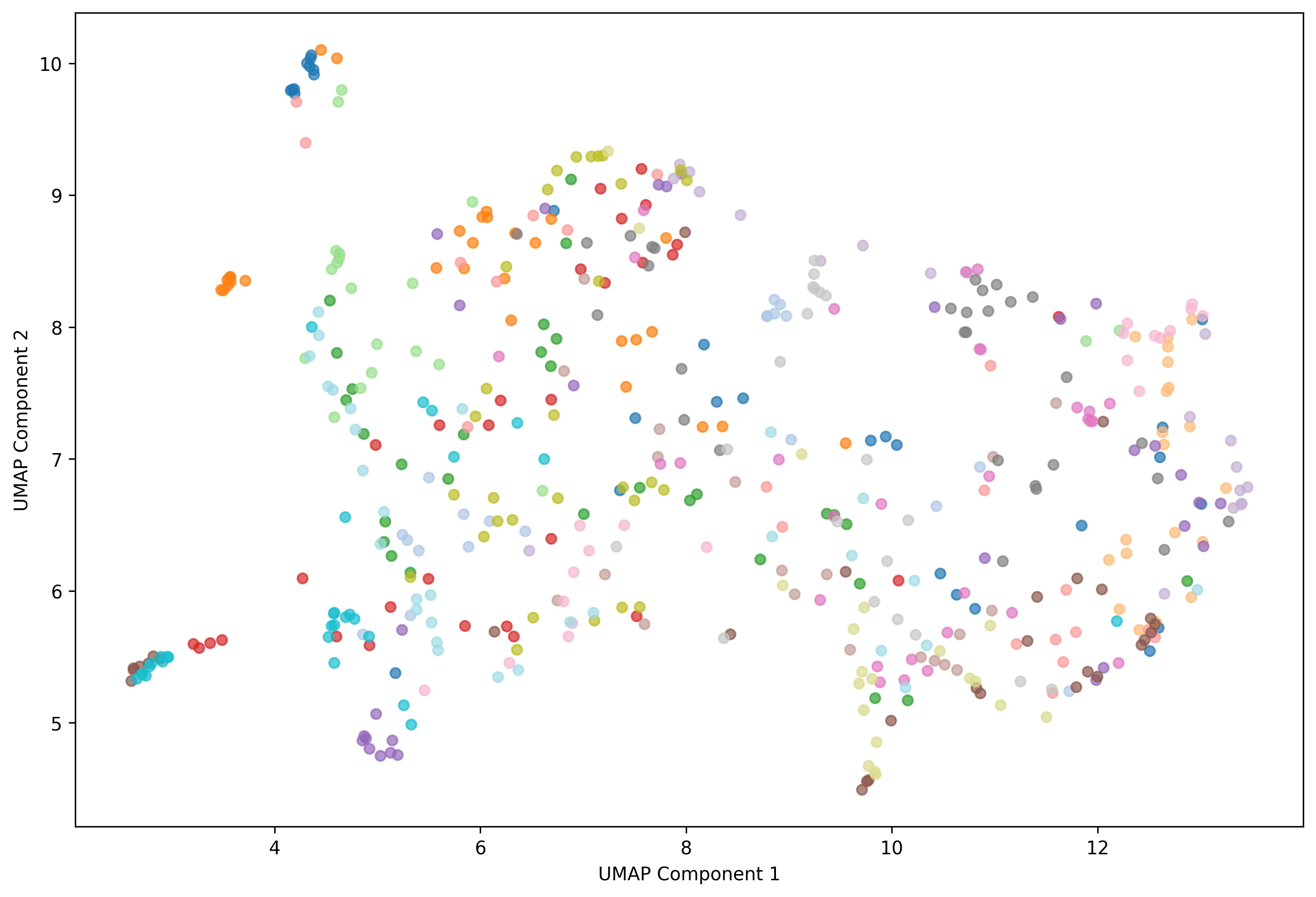
Figure 8 - Distribution des tokens sans amélioration
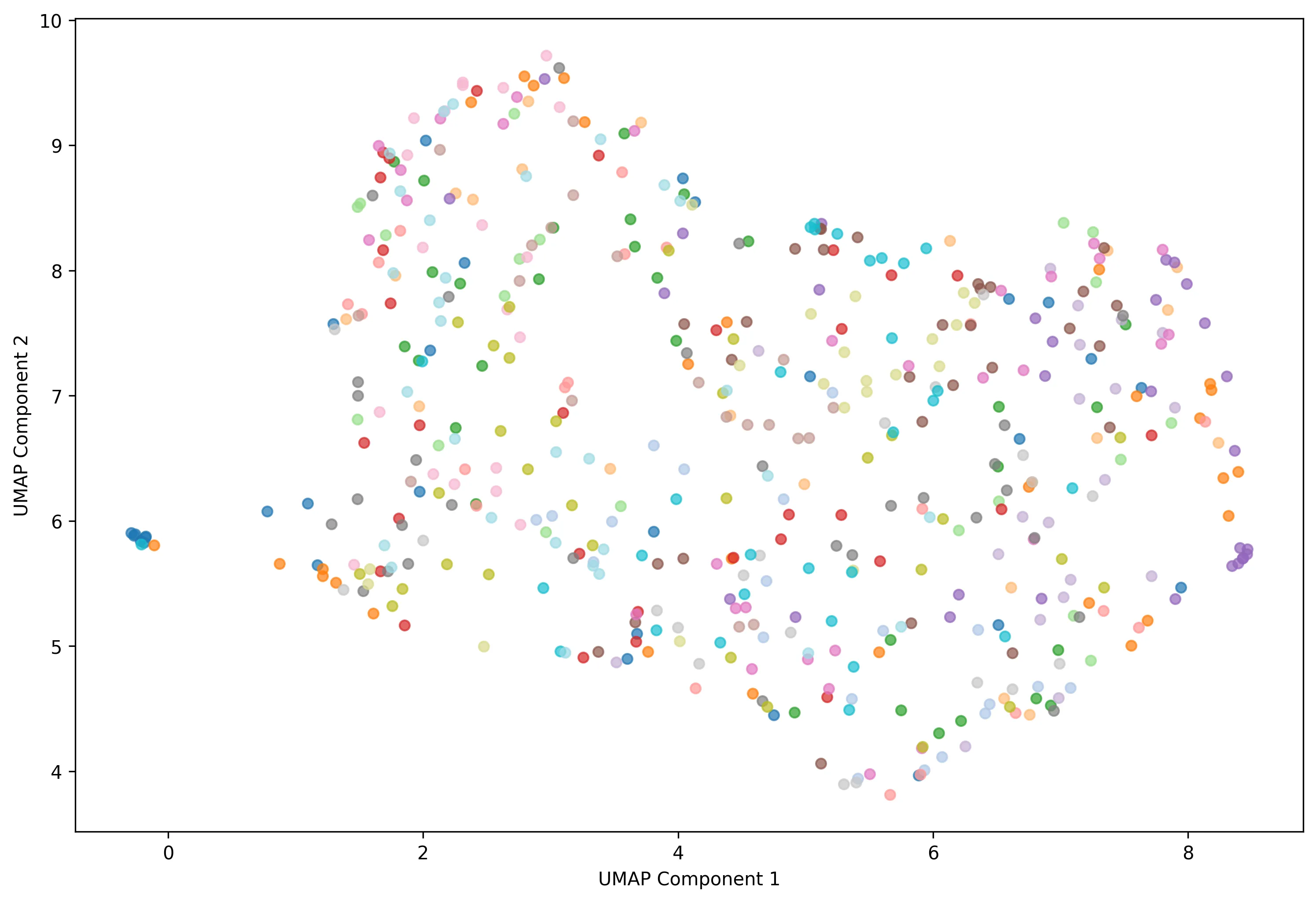
Figure 9 - Distribution des tokens avec amélioration
| Métrique | Sans amélioration | Avec amélioration | Interprétation |
|---|---|---|---|
| Intra-class compactness | 0.143 | 0.192 | Les classes sont plus dispersées après amélioration |
| Inter-class separation | 0.891 | 0.765 | Moins de séparation entre les classes |
| Discriminability ratio | 6.23 | 3.98 | Diminution de la qualité discriminative globale |
| Adjusted Rand Index (ARI) | 0.412 | 0.291 | Moindre correspondance entre clusters et vraies étiquettes |
| Silhouette Score | 0.218 | 0.137 | Les clusters sont moins cohérents |
| Cluster Purity | 0.641 | 0.510 | Plus d’erreurs de regroupement entre classes |
Contrairement à nos attentes, les résultats ont montré une baisse généralisée des performances après amélioration des images. Les classes devenaient moins compactes, les frontières inter-classes plus floues, et les clusters moins distincts. Cela s’explique probablement par trois facteurs :
- CLIP est déjà robuste aux variations visuelles et peut être perturbé par des artefacts introduits artificiellement
- Le décalage de domaine créé par l’amélioration rompt avec les données naturelles sur lesquelles le modèle a été entraîné
- Meta-Net a été optimisé pour des images non modifiées, et ne généralise pas bien lorsque les entrées changent au test
Ainsi, cette expérience souligne que les modèles préentraînés comme CLIP sont conçus pour fonctionner sans ajustement lourd du signal visuel, et que les améliorations naïves en post-traitement peuvent au contraire nuire aux performances. Les techniques d’adaptation doivent être intégrées en amont, lors de la phase d’entraînement initial du modèle, ou faire appel à des stratégies de transfert plus complexes.
Ces projets pourraient vous intéresser

Contrôle de freinage par réseau de neurones
Système ABS intelligent utilisant un contrôleur NARMA-L2.

Traitement de séquences enzymatiques via Deep Learning
Prédire l'activité enzymatique sur différents substrats par réseaux de neurones.