
Few-shot adaptation of the CLIP model to improve image classification on known categories while preserving zero-shot generalization. Comparison of recent approaches (CoOp, CoCoOp) on the Oxford Flowers-102 dataset, with implementation, evaluation, and proposed improvements.
1. Dataset Preparation
We used the Oxford Flowers-102 dataset, composed of 102 flower categories.
- Base classes: First 51 classes (with 10 images per class for few-shot training)
- Novel classes: Last 51 classes (never seen during training)
We applied a strict separation between seen and unseen classes, ensuring good generalization and fair evaluation.

Figure 1 - Sample Images from the Dataset
2. Zero-Shot Evaluation with CLIP
Before any adaptation, we evaluated CLIP’s performance in zero-shot using the following prompt:
prompts = [f"a photo of a {class_name}, a type of flower." for class_name in class_names]This evaluation establishes a baseline to measure the impact of adaptation methods on seen and unseen classes.
| Set | Accuracy (%) |
|---|---|
| Base | 71.33 |
| Novel | 78.26 |
3. CoOp Method: Context Optimization
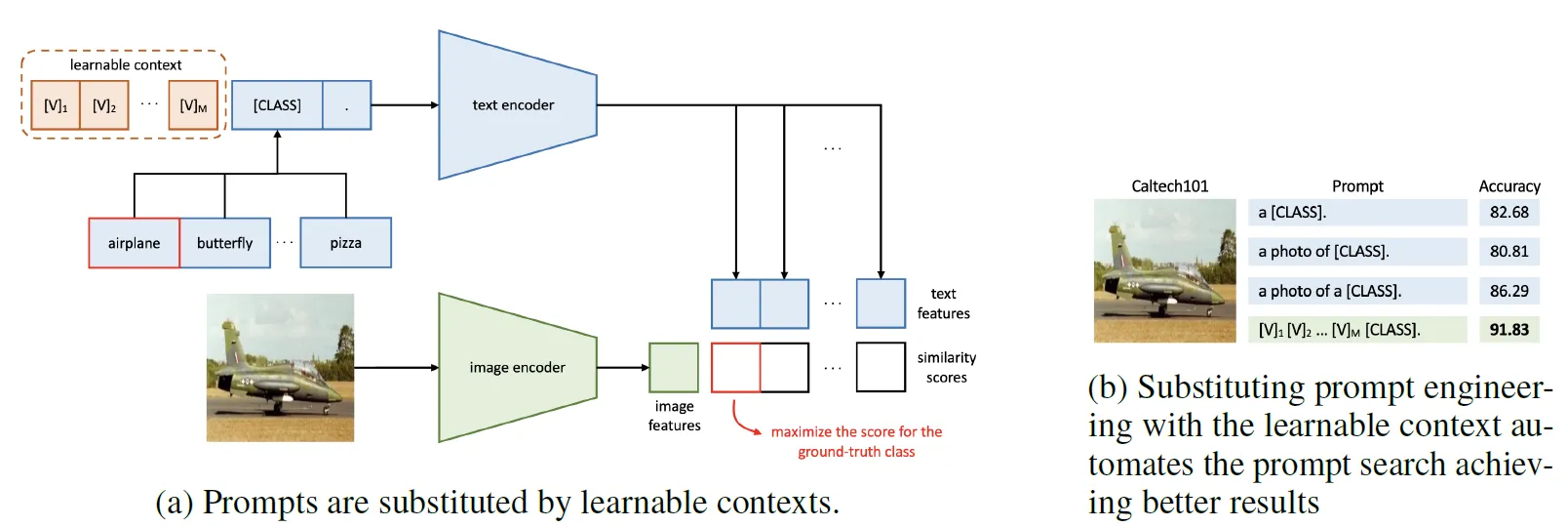
Figure 2 - CoOp Overview
The CoOp approach replaces static text prompts with learnable context vectors, trained only from few-shot training images. The CLIP backbone remains frozen, which greatly reduces the number of trained parameters. Indeed, we observed that fine-tuning mostly leads to overfitting.
- Context vectors: 16 learnable tokens
- Prompt structure:
[CTX_1] [CTX_2] ... [CTX_16] [CLASS]
class PromptLearner(nn.Module):
def __init__(...):
self.ctx = nn.Parameter(torch.empty(n_ctx, ctx_dim))
nn.init.normal_(self.ctx, std=0.02)Results show a clear improvement on base classes but degradation on novel classes due to overfitting:
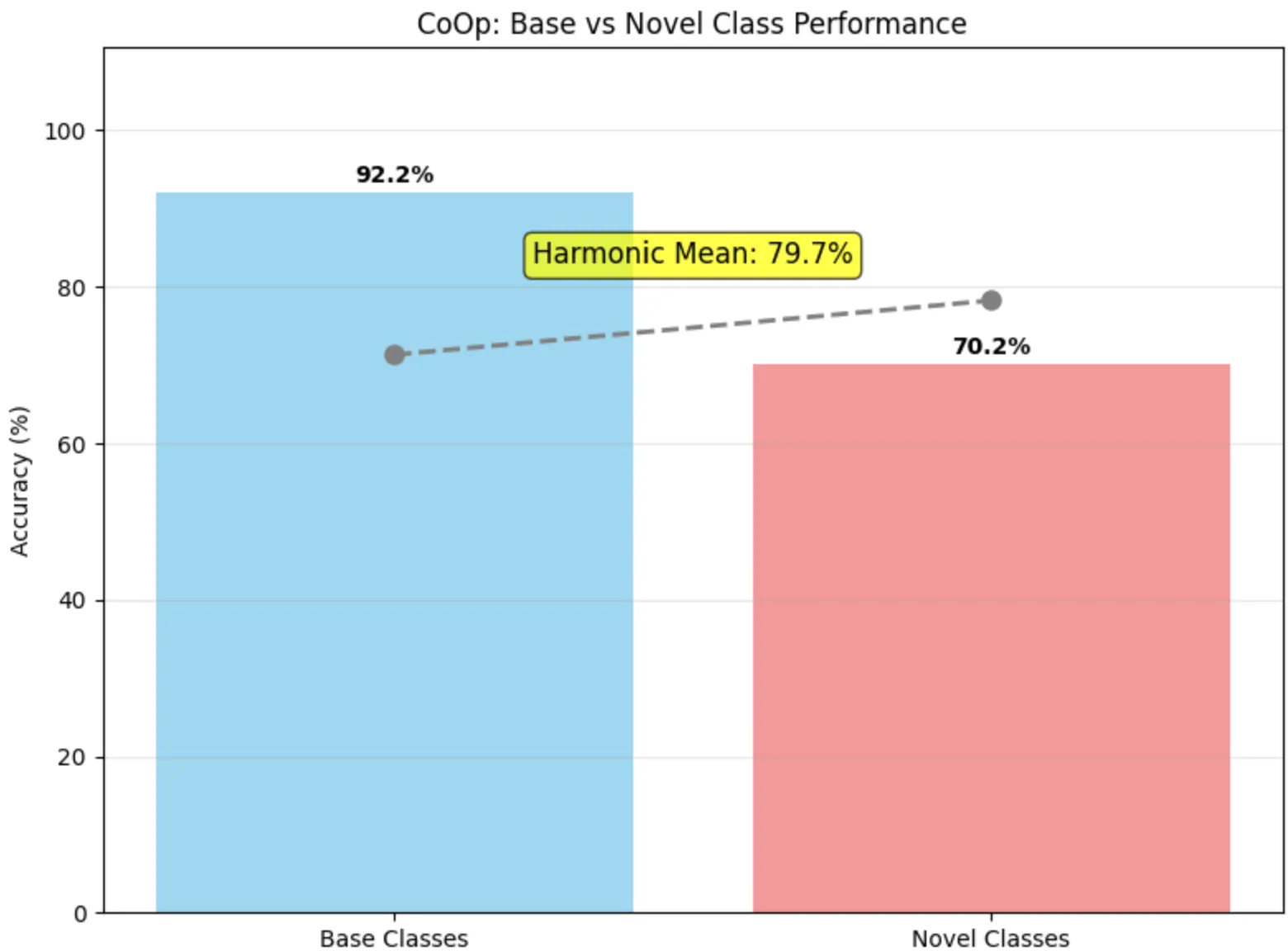
Figure 3 - CoOp Results
4. Improving CoOp: Gaussian Noise
To address over-specialization, we introduced controlled Gaussian noise during context vector learning. This regularization improves robustness and generalization:
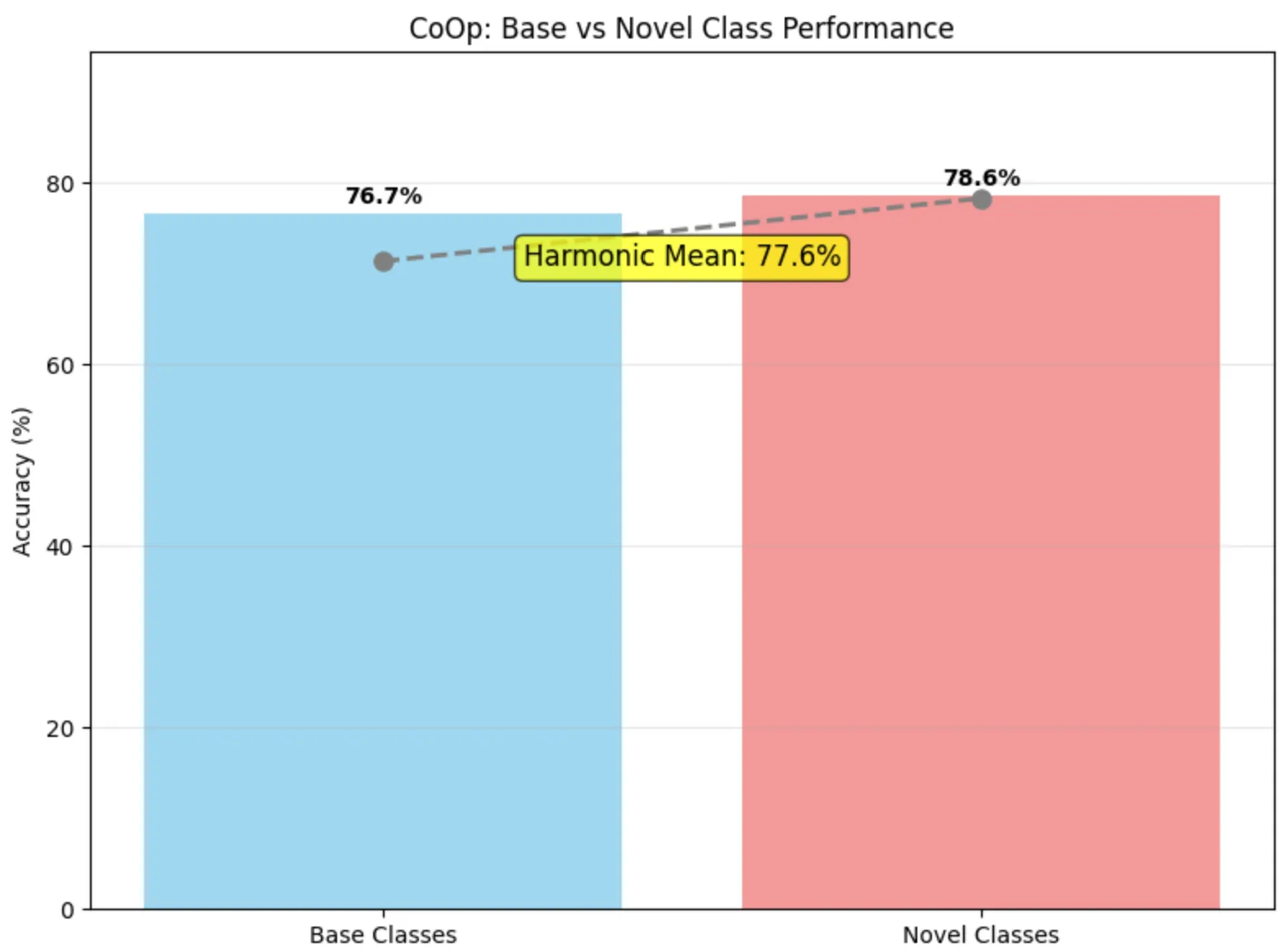
Figure 4 - CoOp Results with Gaussian Noise
| Model | Base (%) | Novel (%) | Harmonic Mean |
|---|---|---|---|
| Raw CoOp | 92.16 | 70.20 | 79.69 |
| CoOp + noise | 76.67 | 78.63 | 77.63 |
if self.training and self.noise_scale:
noise = torch.randn_like(ctx) * (self.noise_scale * max_val)
ctx = ctx + noise5. CoCoOp Method: Conditional Context
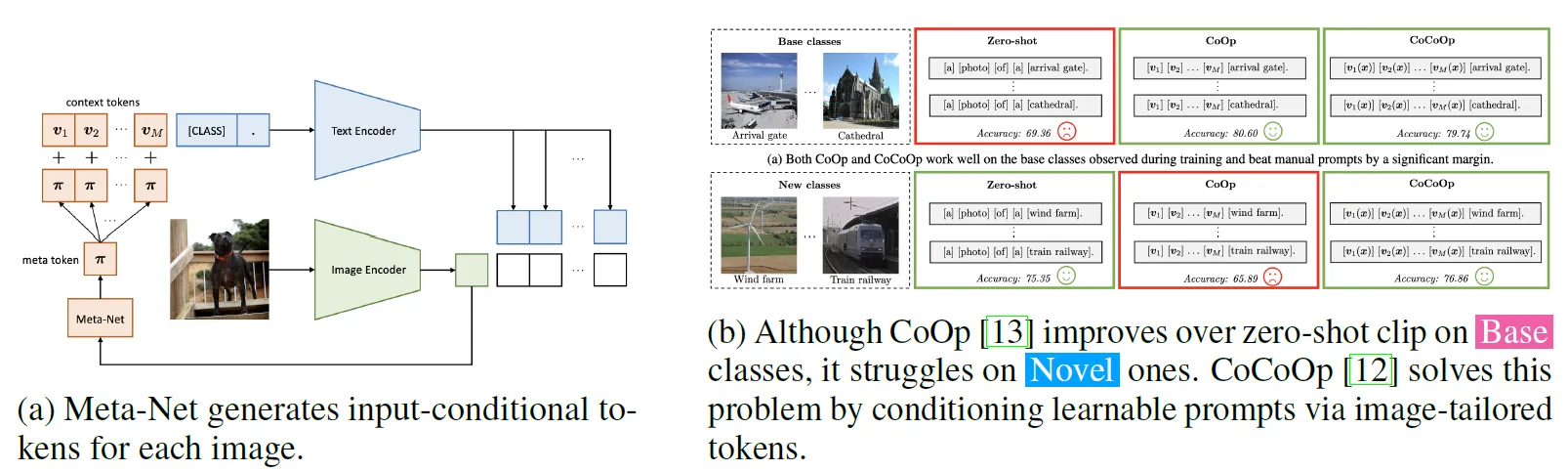
Figure 5 - CoCoOp Overview
We then implemented CoCoOp, which improves CoOp by making context vectors image-dependent via a Meta-Net, a lightweight network conditioning prompts on visual features.
- Contextual base: Fixed vectors as in CoOp
- Meta-Net: Network that generates a conditional bias on each image with a hidden layer that reduces input size by a factor of 16:
ctx_shifted = ctx + self.meta_net(image_features)This method achieves better generalization to novel classes while maintaining high performance on base classes:
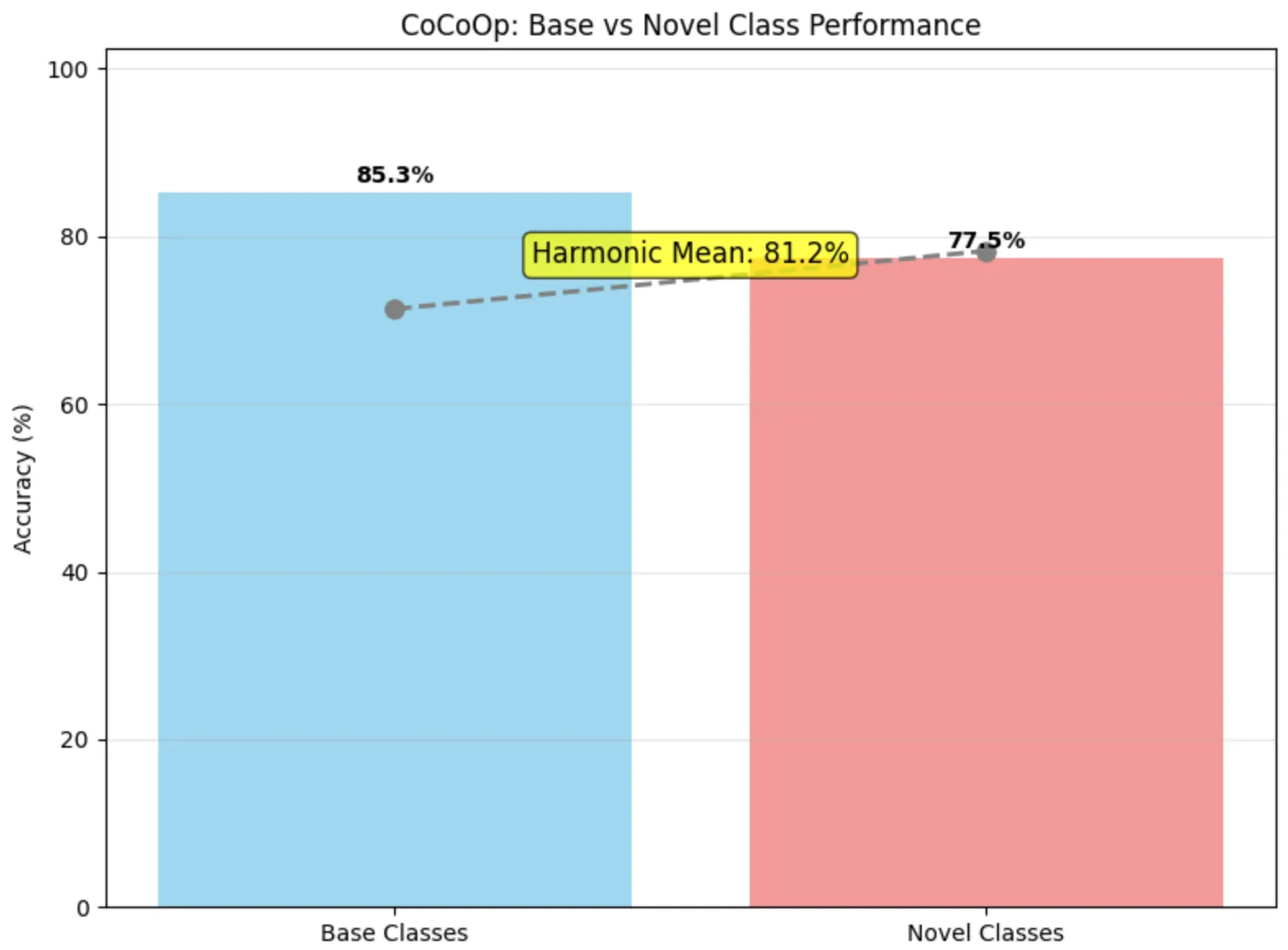
Figure 6 - CoCoOp Results
6. CoCoOp Improvements
We strengthened CoCoOp’s generalization capability by modifying the Meta-Net architecture and keeping the idea of adding Gaussian noise during training:
- Addition of BatchNorm and Dropout
- Replacement of certain activations
- Testing different layer sizes
self.meta_net = nn.Sequential(
nn.Linear(input_dim, hidden),
nn.BatchNorm1d(hidden),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(hidden, ctx_dim)
)These adjustments improved robustness without significantly increasing training cost:
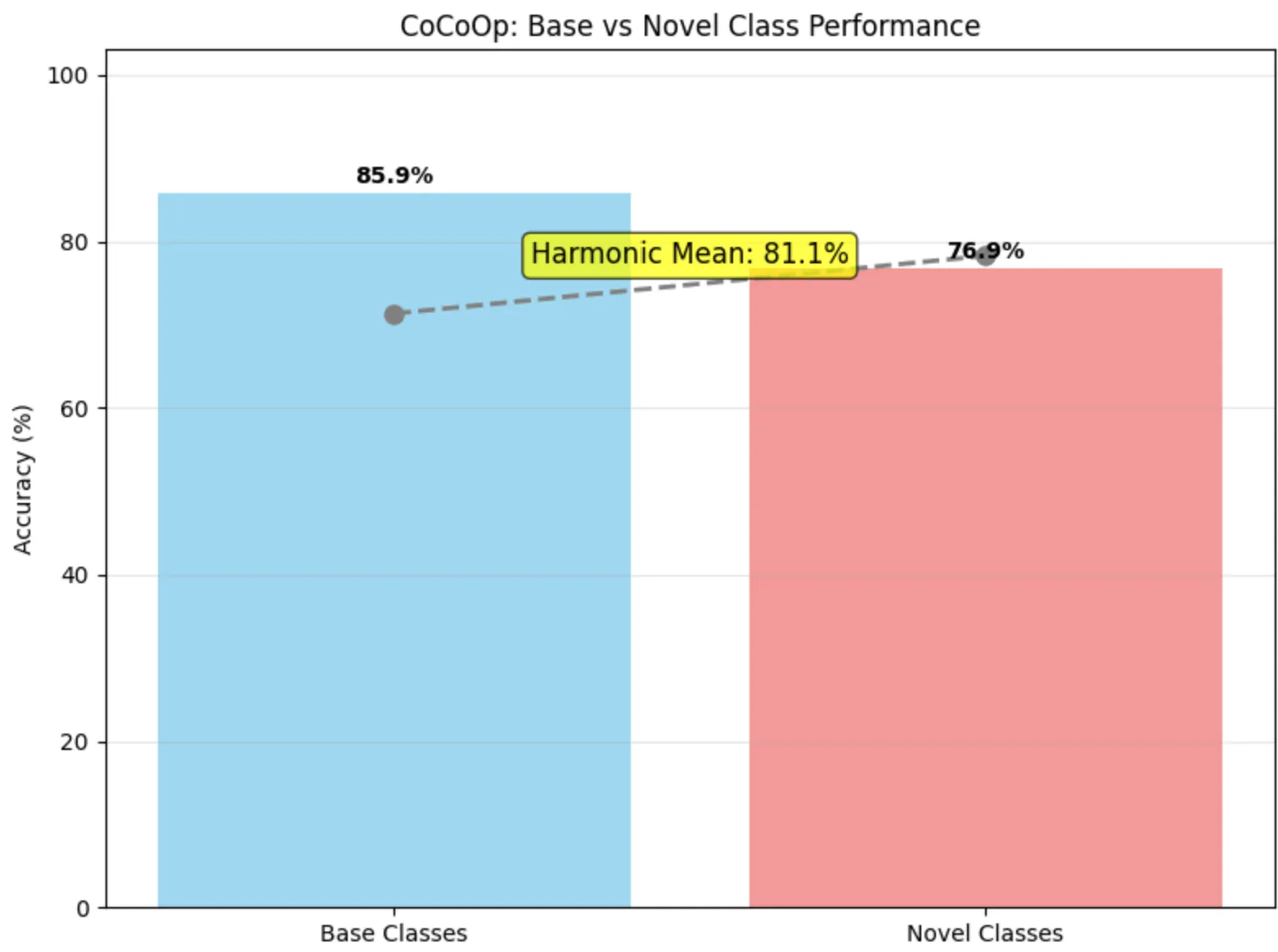
7. Meta-Net Improvement
After training the model with the CoCoOp method, we explored the idea of enhancing images via preprocessing to help the network generate more discriminative conditional tokens. The initial hypothesis is that enhancing visual features (such as more pronounced saturation) could strengthen intra-class clustering (similar flowers close together) and inter-class separation (different flowers far apart), thus improving overall performance.
To do this, we applied adaptive contrast amplification, motivated by biological criteria: flowers are often distinguished by their patterns and colors. We then extracted conditional tokens generated by Meta-Net on raw and modified versions of images, and compared several clustering metrics:
- Intra-class compactness
- Inter-class separation
- Discriminability ratio
- Adjusted Rand Index (ARI)
- Silhouette score
- Cluster purity
We also used the UMAP method to visualize token distribution.
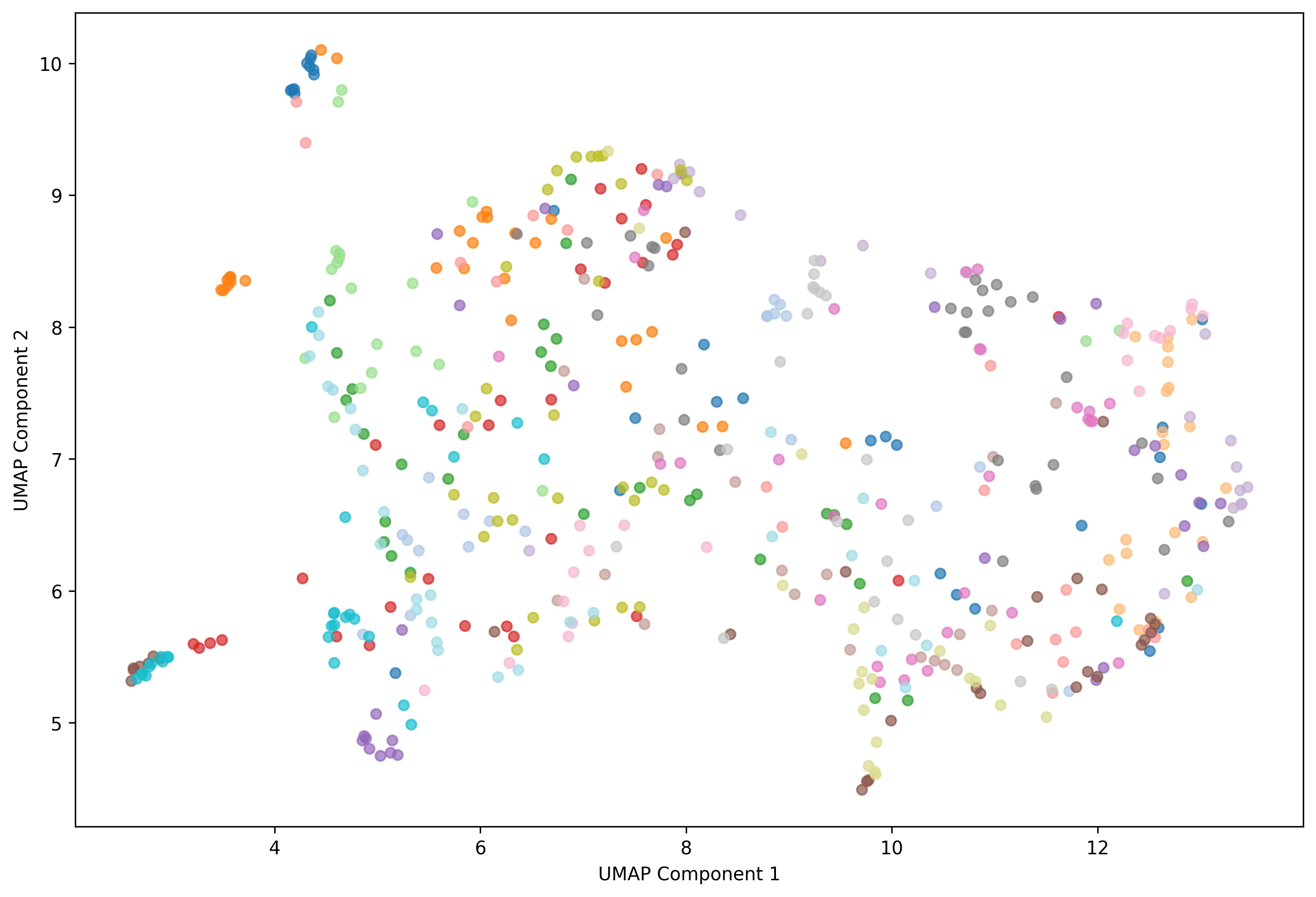
Figure 8 - Token Distribution without Enhancement
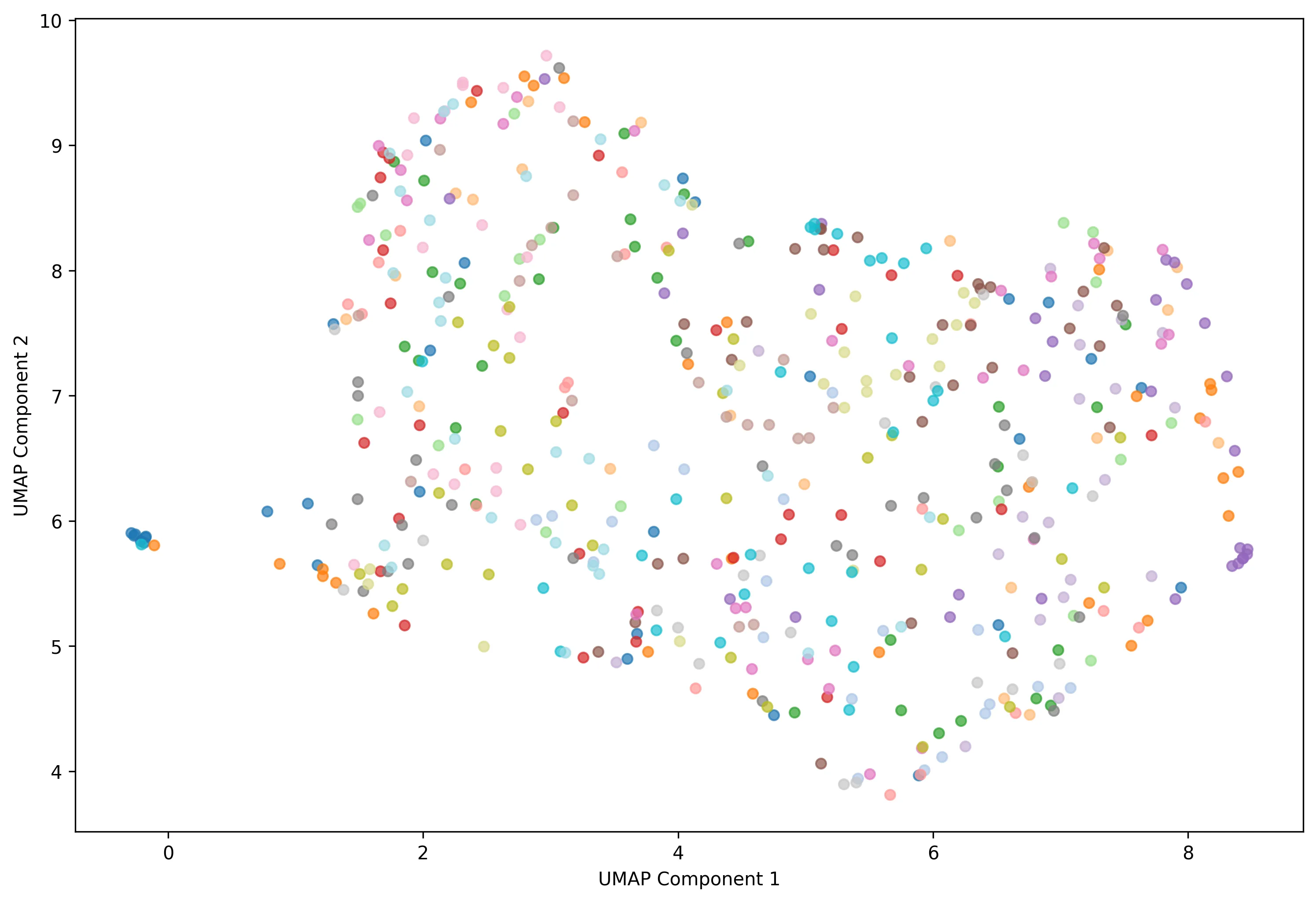
Figure 9 - Token Distribution with Enhancement
| Metric | Without Enhancement | With Enhancement | Interpretation |
|---|---|---|---|
| Intra-class compactness | 0.143 | 0.192 | Classes are more dispersed after enhancement |
| Inter-class separation | 0.891 | 0.765 | Less separation between classes |
| Discriminability ratio | 6.23 | 3.98 | Decrease in overall discriminative quality |
| Adjusted Rand Index (ARI) | 0.412 | 0.291 | Less correspondence between clusters and true labels |
| Silhouette Score | 0.218 | 0.137 | Clusters are less coherent |
| Cluster Purity | 0.641 | 0.510 | More grouping errors between classes |
Contrary to our expectations, results showed a generalized performance decrease after image enhancement. Classes became less compact, inter-class boundaries blurrier, and clusters less distinct. This is probably explained by three factors:
- CLIP is already robust to visual variations and can be disturbed by artificially introduced artifacts
- The domain shift created by enhancement breaks from natural data the model was trained on
- Meta-Net was optimized for unmodified images, and does not generalize well when inputs change at test time
Thus, this experiment highlights that pre-trained models like CLIP are designed to work without heavy visual signal adjustment, and that naive post-processing enhancements can actually hurt performance. Adaptation techniques must be integrated upstream, during the model’s initial training phase, or use more complex transfer strategies.
These projects might interest you

Neural Network Braking Control
Intelligent ABS system using a NARMA-L2 controller.

Processing Enzymatic Sequences via Deep Learning
Predicting enzymatic activity on various substrates using neural networks.