
Serveur MCP (Model Context Protocol) exposant 102 outils de data science à n'importe quel LLM compatible. Du chargement de CSV jusqu'au rapport HTML auto-contenu, un agent piloté en langage naturel conduit le pipeline complet : nettoyage, encodage, modélisation, visualisation, tests statistiques et clustering.
1. Le protocole MCP
Le Model Context Protocol (MCP) est un protocole open-source publié par Anthropic en novembre 2024 pour standardiser la façon dont les LLMs interagissent avec des outils et des sources de données externes. Il s’appuie sur JSON-RPC 2.0 et utilise stdio comme transport : le client démarre le processus serveur et dialogue avec lui via ses flux standards, sans port réseau ni service distant.
Un serveur MCP peut exposer trois primitives : des Tools (fonctions appelables avec des arguments typés), des Resources (données consultables en lecture seule) et des Prompts (templates de conversation). Ce projet utilise exclusivement les Tools et le champ instructions, un texte injecté dans le contexte système du LLM dès la connexion.
Le cycle de vie d’un appel est le suivant : le LLM décide d’appeler un outil, envoie un message JSON-RPC via stdio, le serveur exécute la fonction Python correspondante et retourne un TextContent ou un ImageContent. L’entièreté du raisonnement (quel outil, dans quel ordre, avec quels arguments) reste dans le LLM — le serveur n’a pas de logique d’orchestration propre.
FastMCP est la bibliothèque Python officielle de haut niveau pour MCP. Elle offre un décorateur @mcp.tool() qui introspect la signature Python pour générer automatiquement le schéma JSON Schema de l’outil, et supporte les retours Image (PNG binaire) en plus du texte.
Figure 1 - Vue d’un outil et de ses paramètres dans MCP Inspector
2. Architecture
Le serveur est un processus Python unique sans service externe. Il démarre en quelques secondes avec python -m mcp_data_science et expose immédiatement ses 102 outils.
Le fichier server.py est volontairement minimal (44 lignes) : il instancie un unique objet FastMCP et un unique DataStore, puis délègue l’enregistrement des outils à chaque module. Ce choix garantit que tous les outils partagent le même état tout en restant organisés en modules indépendants.
mcp = FastMCP("mcp-data-science", instructions=_instructions)
store = DataStore()
loading.register_tools(mcp, store)
inspection.register_tools(mcp, store)
# ... 13 autres modulesLe DataStore
Chaque appel MCP est sans état au niveau protocole, mais un pipeline data science est intrinsèquement stateful : les outils se passent des DataFrames et des modèles d’une étape à l’autre. La solution est un objet DataStore singleton, instancié une fois au démarrage et passé par référence à chaque module.
class DataStore:
_frames : dict[str, pd.DataFrame] # DataFrames nommés
_current: str # DataFrame "actif"
_models : dict[str, dict] # modèles ML entraînés
_plots : dict[str, bytes] # plots PNG pour les rapports
_csv_dir: str # répertoire de sortieChaque outil accepte un paramètre df_name: str = "". Si vide, l’outil opère sur le DataFrame courant, ce qui permet au LLM de travailler sans répéter le nom du dataset à chaque appel, tout en supportant les scénarios multi-datasets.
3. Les 15 modules et 102 outils
| Module | Outils | Outils clés |
|---|---|---|
| loading | 11 | load_csv, load_excel, load_parquet, merge_dataframes, pivot_table |
| inspection | 9 | get_head, get_info, quality_report, detect_outliers, get_column_profile |
| cleaning | 9 | drop_duplicates, fill_missing, drop_columns, clip_outliers, bin_column |
| transformation | 9 | create_column, log_transform, normalize, string_clean, polynomial_features |
| encoding | 4 | one_hot_encode, target_encode, label_encode, frequency_encode |
| visualization | 14 | plot_histogram, plot_scatter, plot_correlation_matrix, plot_violin, plot_qq |
| analysis | 8 | get_correlation, group_aggregate, crosstab, detect_outliers |
| modeling | 8 | train_test_split, train_model, evaluate_model, cross_validate, grid_search |
| feature_selection | 4 | variance_filter, correlation_filter, feature_importance, drop_low_importance |
| datetime_tools | 4 | extract_datetime_parts, datetime_diff, datetime_filter, set_datetime_index |
| statistical_tests | 6 | ttest_independent, anova_test, chi_square_test, normality_test, mann_whitney_test |
| interpretation | 7 | plot_feature_importance_model, plot_residuals, plot_confusion_matrix, plot_roc_curve |
| clustering | 5 | kmeans_cluster, dbscan_cluster, elbow_plot, silhouette_score, cluster_profile |
| dimensionality | 2 | pca_transform, tsne_plot |
| reporting | 2 | save_report (Markdown + PNGs), save_report_html (HTML auto-contenu) |
Chaque module suit le même contrat d’interface : les outils ne lèvent jamais d’exception (ils retournent toujours une string, succès ou erreur lisible), les docstrings sont LLM-facing (FastMCP les expose directement dans le schéma JSON), et les mutations passent toujours par store.set().
4. Le pipeline en 13 phases
MCP permet à un serveur d’injecter du texte dans le contexte système du LLM dès la connexion via le champ instructions. Ce projet embarque ainsi un guide de workflow complet (~260 lignes) directement dans le serveur. Le LLM reçoit automatiquement un pipeline structuré en 13 phases, des arbres de décision pour les choix méthodologiques, 12 pièges documentés et un guide de récupération d’erreur, sans aucune configuration côté client.
Phase 1 — Loading & First Look load_csv → get_shape → get_head → get_info
Phase 2 — Exploratory Data Analysis quality_report → get_statistics → plot_histogram
Phase 3 — Statistical Testing normality_test → ttest / anova / chi_square
Phase 4 — Data Cleaning drop_duplicates → fill_missing → clip_outliers
Phase 5 — Feature Engineering create_column → extract_datetime_parts → log_transform
Phase 6 — Categorical Encoding one_hot_encode / target_encode / label_encode
Phase 7 — Feature Selection variance_filter → correlation_filter → feature_importance
Phase 8 — Dimensionality Reduction pca_transform / tsne_plot
Phase 9 — Normalization normalize (seulement pour modèles linéaires/distance)
Phase 10 — Modeling train_test_split → train_model → evaluate_model
Phase 11 — Model Interpretation plot_feature_importance_model → plot_residuals
Phase 12 — Clustering elbow_plot → kmeans_cluster → silhouette_score
Phase 13 — Reporting save_report / save_report_htmlLe guide embarque aussi des arbres de décision pour les choix ambigus : quelle stratégie pour les valeurs manquantes selon leur taux, quel test statistique selon la distribution, quel encodage catégoriel selon la cardinalité. Ces règles permettent à l’agent d’opérer de façon rigoureuse sans intervention humaine.
5. Visualisation et reporting
MCP supporte nativement les retours binaires (ImageContent) en plus du texte. Pour la data science, c’est indispensable : une heatmap de corrélation ou un QQ-plot ne peut pas être communiqué par du texte. Tous les outils de visualisation utilisent le backend Agg de matplotlib (rendu headless, sans interface graphique) et retournent directement un objet Image via io.BytesIO, sans écriture disque.
Une variante fig_to_image_and_store() stocke également les bytes PNG dans DataStore._plots pour les réutiliser dans le rapport final sans les regénérer.
save_report_html produit un fichier HTML unique avec les plots embarqués en base64, aucune dépendance externe, prêt à partager. Le rendu suit une structure en 8 sections (Executive Summary, Data Overview, Exploratory Analysis, Statistical Tests, Cleaning Log, Feature Engineering, Modeling Results, Conclusions) avec un design system complet (CSS custom properties, typographie, responsive 900px).
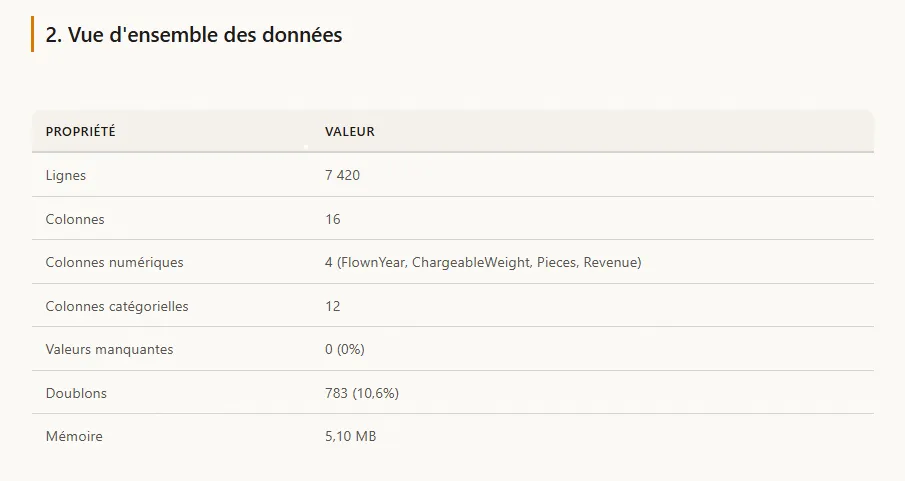
Figure 2 - Vue d’ensemble des données dans le rapport HTML généré
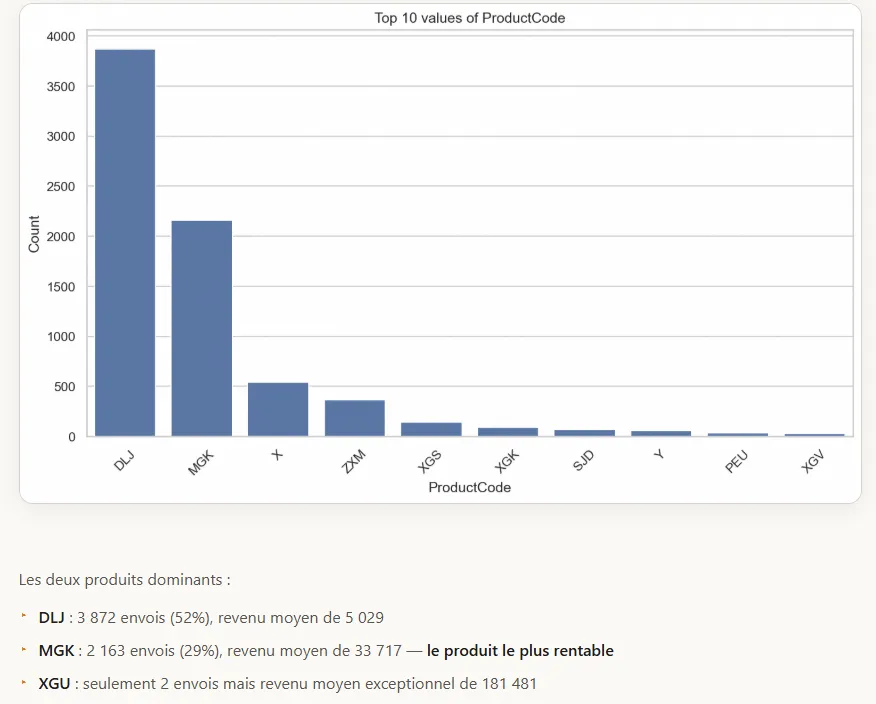
Figure 3 - Graphique généré et analyse associée dans le rapport HTML
6. Exemple d’utilisation
L’utilisateur demande en langage naturel : “Charge ventes_2024.csv, fais un rapport qualité, nettoie les données, entraîne un Random Forest pour prédire le chiffre d’affaires et génère un rapport HTML.” Claude orchestre alors une vingtaine d’appels d’outils dans le bon ordre, en s’appuyant sur le guide de 13 phases embarqué dans le serveur.
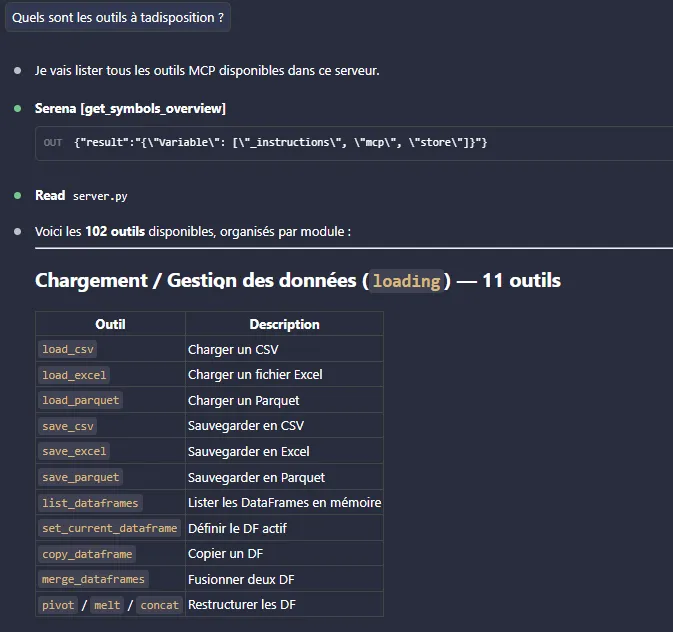
Figure 4 - Utilisation au sein de Claude Code
Ces projets pourraient vous intéresser

Exploration d'un Pipeline RAG
Benchmark d'un pipeline RAG et assemblage de l'outil dans un chat Chainlit.
 2024
2024Faire Parler les Données Médicales
Exploiter les dossiers patients non structurés avec OCR et NLP pour le GIP SIB.