
Exploration systématique d'un pipeline de Retrieval-Augmented Generation avec des outils open-source. 10 notebooks benchmarkent chaque composant (chunking, embeddings, retrieval, reranking, query translation, routing, patterns avancés, évaluation RAGAS), puis une application Chainlit assemble les meilleurs choix en un chat local et streamé.
1. Architecture du pipeline
Le projet assemble un pipeline RAG complet qui transforme une question en réponse sourcée en quatre étapes : découper la documentation en chunks, les vectoriser dans une base, retrouver les plus pertinents face à une requête, puis les passer à un LLM qui génère sa réponse en s’appuyant uniquement sur ce contexte. Chaque étape est isolée dans un notebook dédié, benchmarkée avec plusieurs alternatives, et évaluée sur un jeu standardisé de 25 questions avec réponses expertes.
Le corpus est la documentation Python de LangChain (~1 463 pages récupérées depuis GitHub). Après nettoyage (suppression du frontmatter YAML, des balises MDX/JSX, des blobs base64, normalisation des espaces) et filtrage des pages d’intégrations (90% du corpus), on conserve ~130 documents de fond qui forment ~1 500 chunks.
Tout tourne en local sans appel API : Mistral 7B via Ollama pour la génération, mxbai-embed-large pour les embeddings, ChromaDB pour le stockage vectoriel, un cross-encoder pour le reranking. Le pipeline entier est configurable par un fichier YAML unique :
retrieval:
strategy: hybrid
dense:
search_type: similarity
k: 10
sparse:
k: 10
hybrid:
weights: [0.5, 0.5]
final_k: 5
reranking:
enabled: true
model: cross-encoder/ms-marco-MiniLM-L-6-v2
top_k: 5
query_translation:
enabled: false
routing:
enabled: falseChanger la stratégie de retrieval, activer le reranking ou basculer sur un autre modèle d’embedding se fait sans toucher au code.
2. Chunking et embeddings
a) Chunking
Cinq stratégies de découpage ont été comparées. Le recursive splitter (qui découpe par \n\n, puis \n, puis . , puis ) offre le meilleur compromis : rapide (0.24s), bon MRR (0.467), et chunks de taille homogène (~786 chars).
Un grid search sur la taille (500-2000) et l’overlap (0-400) confirme que 1000/200 est le point optimal. Au-delà de 200 d’overlap, les gains sont négligeables.
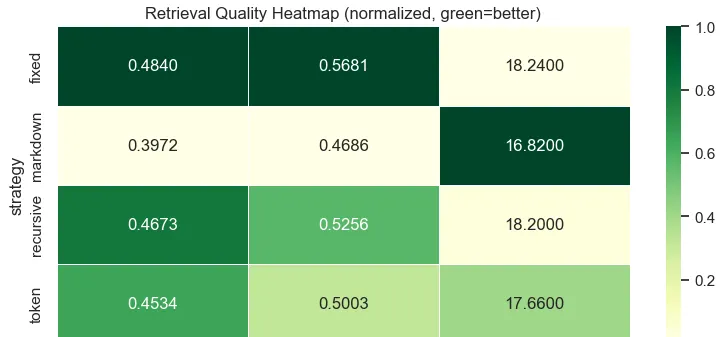
Figure 1 - Heatmap de la qualité de retrieval selon les paramètres de chunking
b) Embeddings
Quatre modèles d’embedding ont été évalués. Le critère décisif n’est pas le MRR brut (non comparable entre modèles) mais la séparation sémantique : l’écart de similarité cosine entre paires pertinentes et non pertinentes.
| Modèle | Dims | Débit (docs/s) | Séparation sémantique |
|---|---|---|---|
| all-MiniLM-L6-v2 | 384 | 102.3 | 0.131 |
| nomic-embed-text | 768 | 174.1 | 0.100 |
| BAAI/bge-small-en-v1.5 | 384 | 27.2 | 0.181 |
| mxbai-embed-large | 1024 | 72.8 | 0.207 |
mxbai-embed-large domine avec 0.207 contre 0.100 pour nomic-embed-text, soit +107% de capacité à discriminer les documents pertinents. C’est le choix retenu pour la suite.
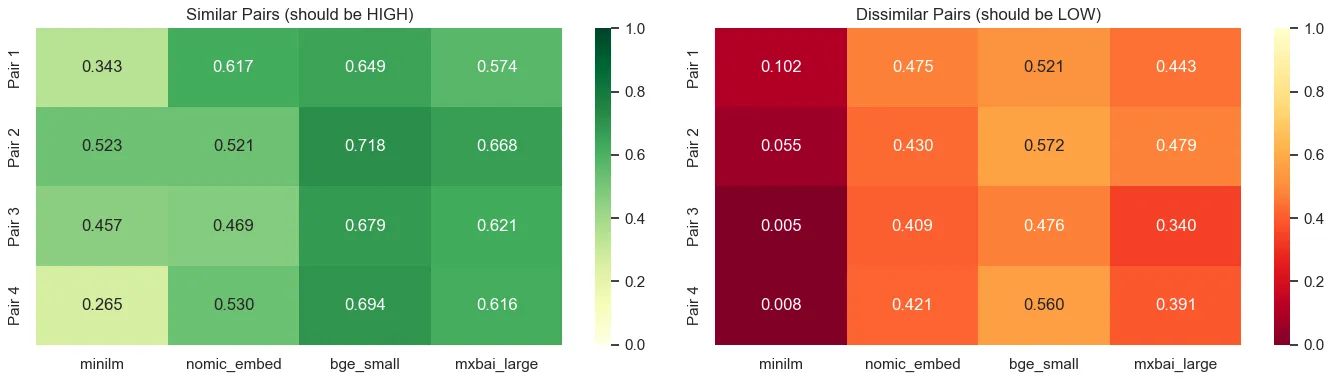
Figure 2 - Séparation sémantique par modèle d’embedding et par question
3. Stratégies de retrieval
Cinq stratégies ont été benchmarkées. BM25 seul est insuffisant pour des requêtes sémantiques (MRR 0.30 vs 0.60 pour le dense), mais combiné au dense via Reciprocal Rank Fusion, il capture à la fois les correspondances sémantiques et les mots-clés exacts. C’est essentiel pour les requêtes techniques contenant des noms de classes ou de fonctions.
MMR avec lambda=0.9 est marginalement meilleur que la similarity pure (MRR 0.605 vs 0.597), mais la diversité forcée à lambda plus bas dégrade les résultats. Le Multi-Query ajoute 100x de latence (5s) sans amélioration.
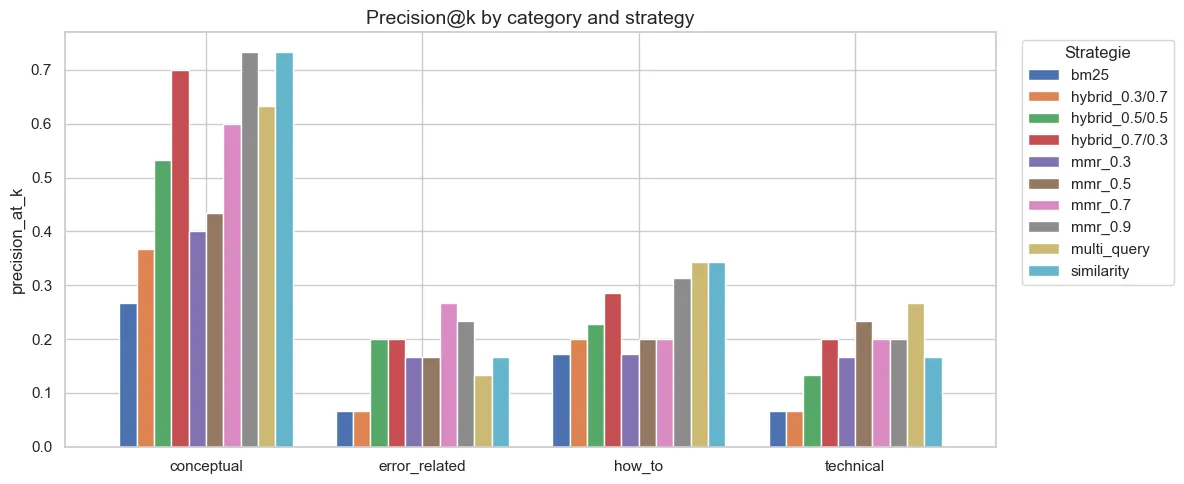
Figure 3 - Précision de retrieval par catégorie de question et par stratégie
Les questions conceptuelles sont bien traitées par toutes les stratégies. Les questions techniques restent les plus difficiles dans toutes les configurations, une limite du corpus (peu de pages de référence API survivent au filtrage des intégrations).
4. Techniques avancées : ce qui échoue avec un modèle 7B
Plusieurs techniques conçues pour des modèles frontier (GPT-4, Claude) ont été testées avec Mistral 7B. Le constat est clair : la plupart échouent ou dégradent les résultats.
En query translation, cinq techniques de reformulation ont été comparées. HyDE (générer une réponse hypothétique puis l’encoder) est la seule qui améliore le retrieval (+6.7% MRR), mais à 141x le coût en latence (2.7s vs 19ms). Multi-Query et Decomposition dégradent les résultats de -9% et -10% respectivement parce que Mistral 7B génère des variantes imprécises ou redondantes.
En routing, diriger les requêtes vers des sous-index par catégorie produit une chute de 38% du MRR, même avec 76% de précision de routage. La cause est un déséquilibre du corpus : après filtrage, les tutoriels comptent 1 656 chunks contre 1 seul chunk pour la référence API.
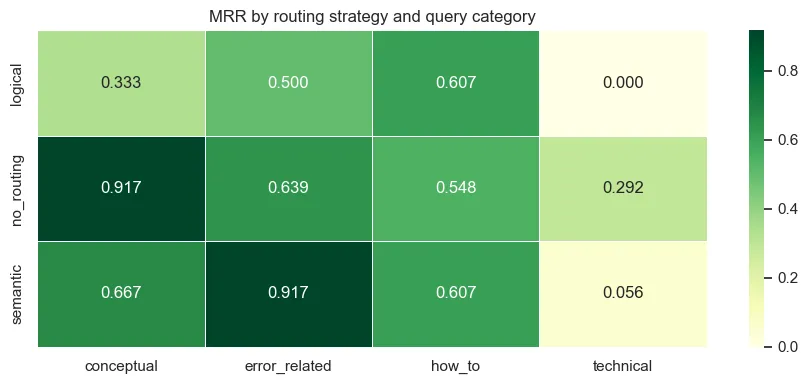
Figure 4 - MRR par stratégie de routing et par catégorie de requête
En patterns avancés (implémentés avec LangGraph), trois architectures ont été testées. CRAG (Corrective RAG : noter chaque document, réécrire la requête si moins de 50% sont pertinents) atteint un MRR parfait de 1.000, mais à 450x la latence (8s vs 18ms). Self-RAG est cassé : Mistral 7B décide systématiquement que le retrieval n’est pas nécessaire et hallucine. Adaptive RAG est également cassé : le classifieur de complexité étiquette toutes les requêtes comme “modérées”.
Le pattern : CRAG fonctionne parce que sa tâche LLM est simple (noter oui/non). Self-RAG et Adaptive RAG demandent du méta-raisonnement hors de portée d’un modèle 7B. Ces techniques sont désactivées dans le pipeline final.
5. Reranking
Le reranking consiste à retrouver 20 candidats puis à les re-scorer avec un cross-encoder pour n’en garder que les 5 meilleurs. Les métriques de retrieval brutes ne montrent qu’un gain modeste (Precision@5 : 0.376 vs 0.352), mais c’est l’évaluation RAGAS qui révèle son vrai impact : +20% de faithfulness et +19% de relevancy. Le cross-encoder ne change pas forcément le rang des documents, mais il remonte ceux qui permettent au LLM de mieux répondre.
Le LLM-as-Judge montre le plafond théorique (MRR 0.90) mais coûte 20 appels LLM par requête (~8s), ce qui est prohibitif.
6. Évaluation RAGAS
RAGAS évalue quatre métriques complémentaires : la faithfulness (la réponse suit-elle le contexte ?), la relevancy (la réponse est-elle pertinente ?), la context precision (les documents retrouvés sont-ils pertinents ?) et le context recall (a-t-on retrouvé tout ce qui est pertinent ?).
| Configuration | Faithfulness | Relevancy | Ctx Precision | Ctx Recall | Moyenne |
|---|---|---|---|---|---|
| Naive (similarity seule) | 0.747 | 0.603 | 0.996 | 0.782 | 0.782 |
| Hybrid + Reranked | 0.947 | 0.793 | 0.973 | 0.770 | 0.871 |
| HyDE | 0.869 | 0.666 | 0.990 | 0.673 | 0.799 |
Le pipeline hybrid + reranked domine avec 0.871 de moyenne, pour seulement +35% de latence par rapport au naive. HyDE est le pire compromis : 2.7x plus lent avec le recall le plus bas. Le gap de +0.09 entre naive et hybrid+reranked provient entièrement de la qualité du retrieval qui fournit un meilleur contexte au LLM.
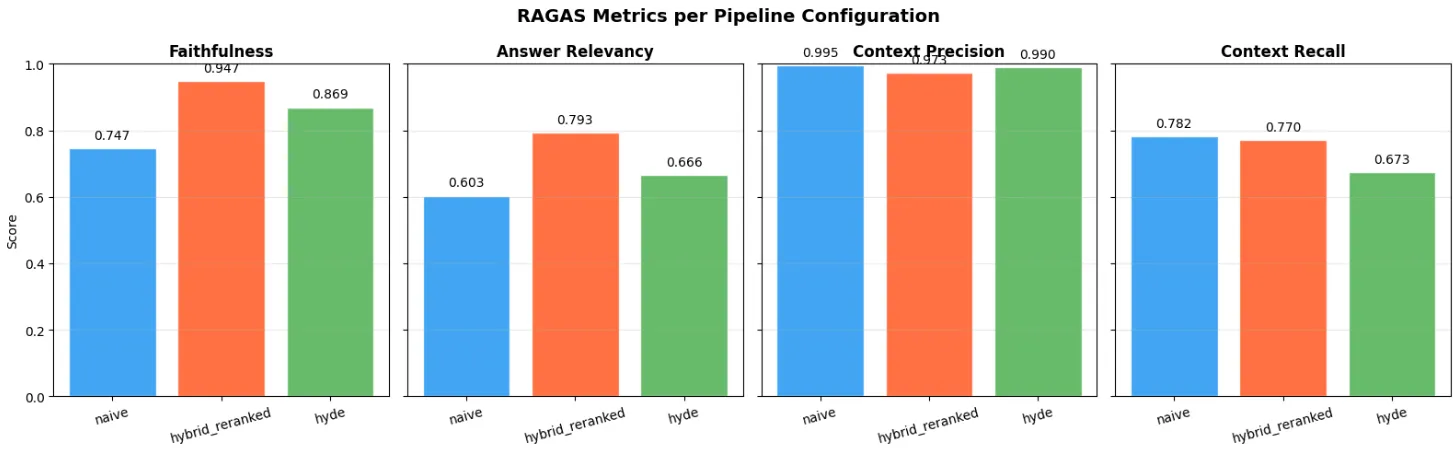
Figure 5 - Métriques RAGAS par configuration de pipeline
7. Pipeline final et interface Chainlit
Le pipeline de production assemble les meilleurs choix : recursive chunking (1000/200), mxbai-embed-large, hybrid retrieval BM25+Dense avec RRF, cross-encoder reranking, et Mistral 7B en génération. Query translation, routing et patterns avancés sont désactivés car ils n’apportent rien ou dégradent les résultats avec un modèle 7B.
L’interface Chainlit propose quatre modes (Simple, Hybrid, Hybrid+Rerank, Direct LLM), un panneau de paramètres interactif (nombre de résultats, affichage des sources, mémoire de conversation), et le streaming token par token. Chaque réponse affiche ses sources dans des panneaux cliquables qui révèlent le chunk complet retrouvé, ainsi que les métriques de timing (retrieval, génération, total).
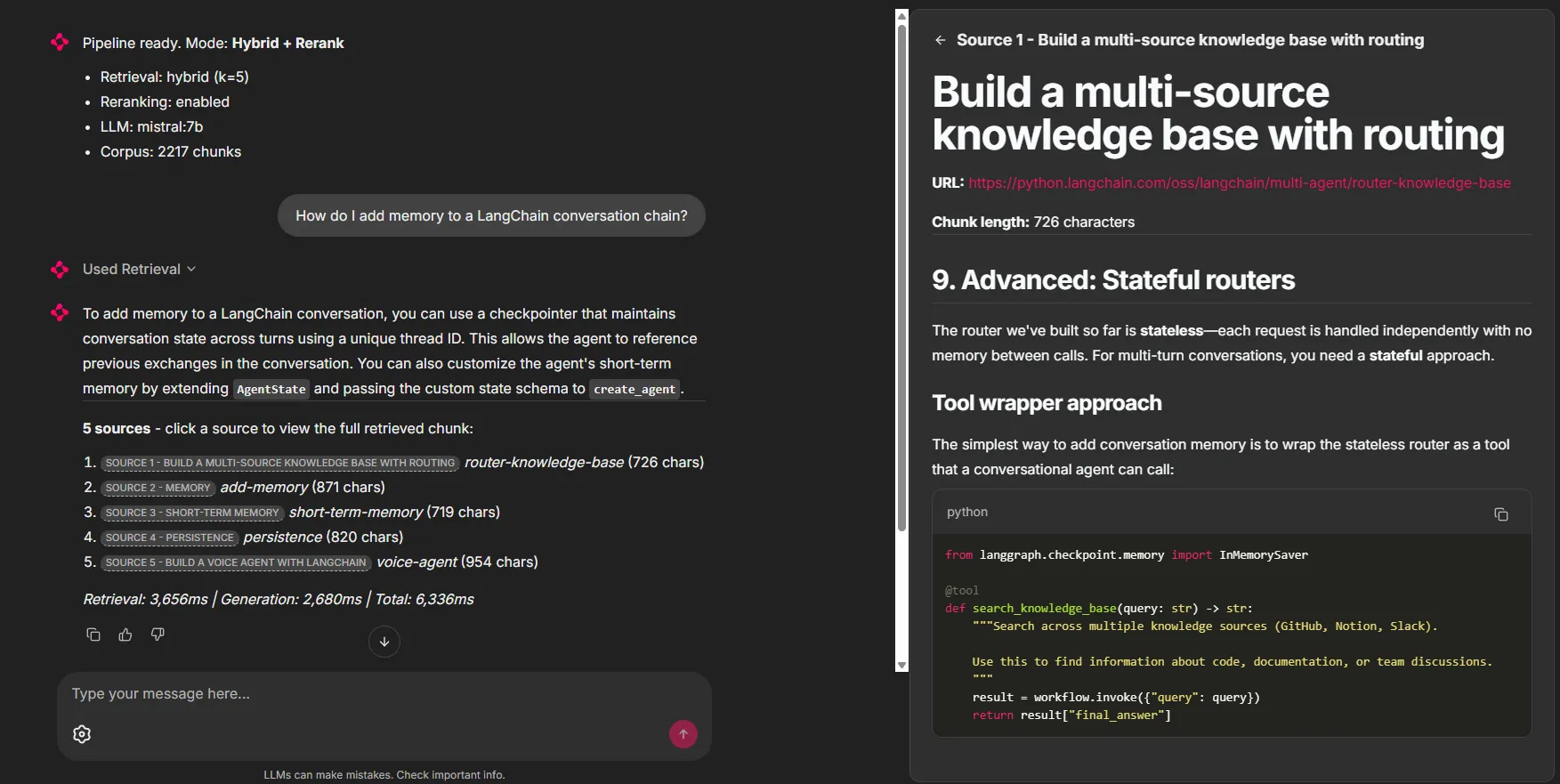
Figure 6 - Réponse du pipeline à une question sur la mémoire conversationnelle, avec les 5 sources et les temps de retrieval/génération
Sur les 25 questions du benchmark final, le pipeline atteint un score RAGAS moyen de 0.874 (faithfulness 0.919, relevancy 0.846, context precision 0.954, context recall 0.777) avec une latence moyenne de 3.5s. La génération (inférence Mistral 7B, ~3.2s) représente 91% de la latence totale. Le retrieval incluant le reranking ne pèse que ~300ms.
Ces projets pourraient vous intéresser

MCP Data Science
102 outils de data science pilotés en langage naturel via le protocole MCP d'Anthropic.

OpenWhisper
Transcrire la voix en texte en temps réel, 100% en local, via faster-whisper et Tauri.