
Application desktop de transcription vocale en temps réel, 100% locale, propulsée par faster-whisper (OpenAI Whisper via CTranslate2). Architecture deux couches Tauri v2 + React communiquant avec un backend Python FastAPI, offrant dictée, transcription live, upload de fichiers, recherche sémantique et post-traitement LLM.
1. Architecture
Le système repose sur une architecture à deux couches :
- Tauri v2 (Rust) : shell desktop natif gérant les raccourcis globaux, le system tray, l’overlay always-on-top et l’injection de texte
- FastAPI (Python) : backend hébergeant faster-whisper, la capture audio, le stockage SQLite, la recherche sémantique ChromaDB et le client LLM
Le frontend React connecte ces deux couches via HTTP et WebSocket côté backend, et via l’IPC Tauri (événements et commandes) côté shell Rust.

Figure 1 - Architecture du système
Le choix de Tauri permet d’obtenir un binaire de 5 à 10 MB (contre ~150 MB avec Electron) et une consommation mémoire réduite (~50-80 MB au repos). Le backend Python séparé donne accès à l’écosystème IA (faster-whisper, ChromaDB, OpenAI SDK) tout en communiquant par WebSocket pour le streaming temps réel.
2. Pipeline de transcription
Le pipeline transforme l’audio du microphone en texte, en continu.
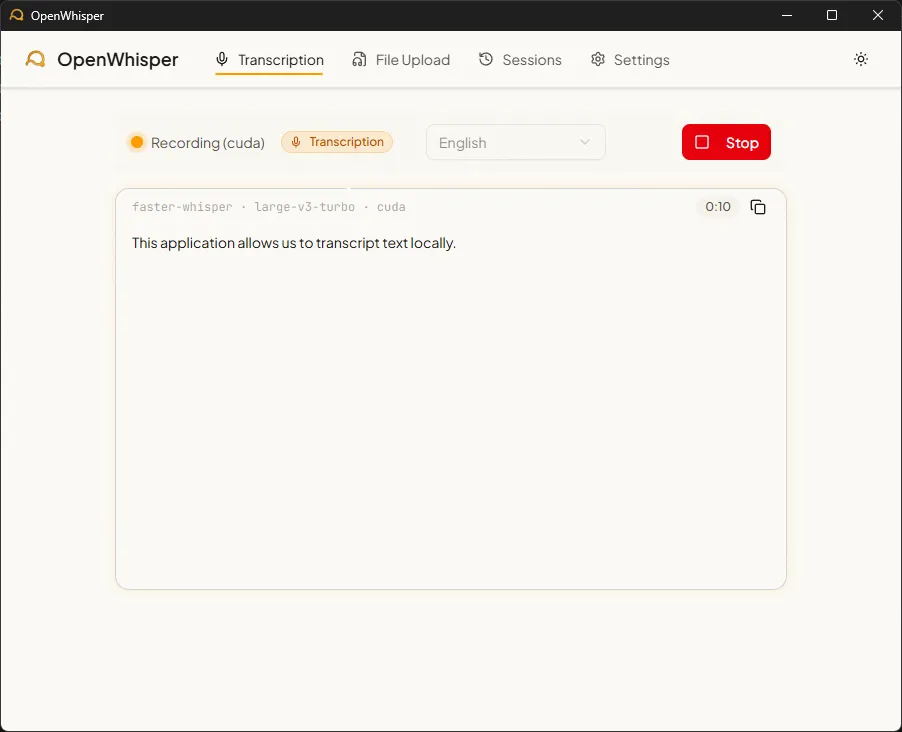
Figure 2 - Mode transcription en temps réel
Microphone → sounddevice (16kHz mono)
→ chunks PCM16 de 80ms → base64 → WebSocket
→ buffer circulaire (10s, overlap 1s)
→ Silero VAD (filtrage silence)
→ faster-whisper (beam search, beam=5)
→ filtrage anti-hallucination
→ delta texte → frontendL’audio est capturé à 16 kHz mono via PortAudio, découpé en chunks de 80ms, encodé en base64 et transmis par WebSocket. Le backend accumule ces chunks dans un buffer configurable (1 à 30 secondes, défaut 10s) avec un overlap d’une seconde entre les fenêtres pour éviter de couper les mots.
Anti-hallucination
Les modèles Whisper peuvent produire des hallucinations : boucles de texte répété ou phrases inventées sur des segments silencieux. Trois mécanismes de filtrage sont en place :
- Filtrage par compression ratio et log_prob : les segments dont le ratio de compression dépasse un seuil ou dont la log-probabilité moyenne est trop basse sont rejetés
- Détection de n-grams répétés : si un même n-gram apparaît plus de 3 fois dans un segment, le chunk entier est ignoré
- Silero VAD : le Voice Activity Detector filtre les régions silencieuses en amont, empêchant Whisper de transcrire du silence
CPU vs GPU
| Configuration | Modèle | Latence (10s d’audio) | VRAM |
|---|---|---|---|
| CPU (i7/Ryzen 7) | small (244M params) | 3-5 s | 0 |
| CPU | large-v3-turbo (809M) | 15-30+ s | 0 |
| GPU (RTX 3060+) | large-v3-turbo | ~1 s | ~3 GB |
| GPU | small | < 1 s | ~500 MB |
Le mode auto détecte la présence d’un GPU CUDA et sélectionne le modèle optimal. En cas d’échec CUDA (DLL manquante, VRAM insuffisante), le fallback vers CPU est automatique.
3. Modes d’utilisation
a) Mode dictée
Figure 3 - Mode dictée
Le raccourci global Ctrl+Shift+D active la transcription. Chaque fragment de texte est injecté à la position du curseur dans l’application active. L’injection utilise le clipboard (via arboard) puis simule Ctrl+V (via enigo), ce qui assure la compatibilité Unicode et une vitesse supérieure à la simulation de frappes individuelles. Les deltas sont regroupés par lots de 80ms pour éviter les conflits de clipboard.
b) Mode transcription
Le raccourci Ctrl+Shift+T ouvre la fenêtre de transcription dédiée. Le texte s’accumule dans une vue scrollable avec un timer de session. À la fin, la session est sauvegardée en SQLite avec des segments horodatés et indexée dans ChromaDB.
c) Mode upload
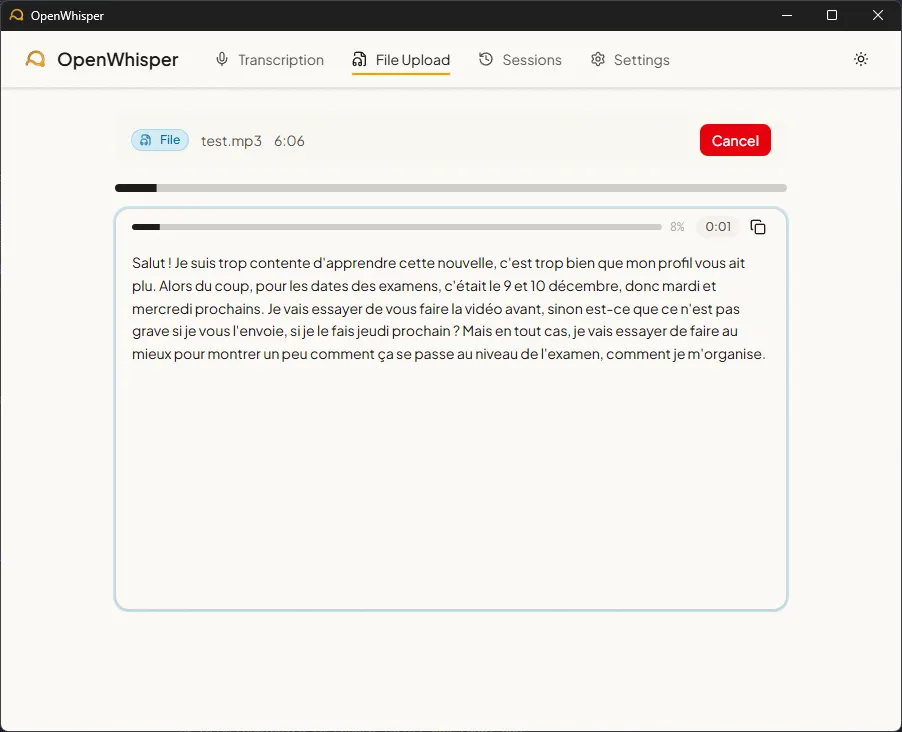
Figure 4 - Transcription de fichier audio
Le drag-and-drop ou le sélecteur de fichier accepte 9 formats audio (WAV, MP3, FLAC, OGG, M4A, WebM, WMA, AAC, Opus) jusqu’à 500 MB. L’upload REST crée la session et sauvegarde le fichier temporaire, puis le WebSocket stream la progression et les segments en temps réel. En GPU, un enregistrement de 6 minutes est transcrit en 9 secondes, soit environ 40x plus rapide que le temps réel.
4. Recherche sémantique
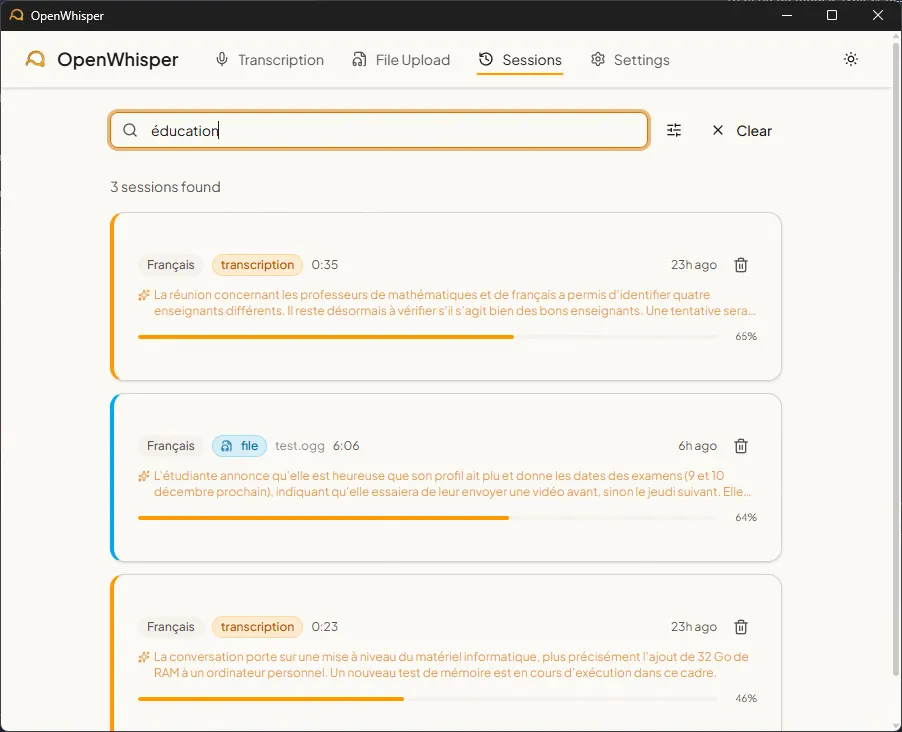
Figure 5 - Recherche dans l’historique des sessions
Les sessions sont indexées dans ChromaDB avec des embeddings multilingues (paraphrase-multilingual-MiniLM-L12-v2, 384 dimensions, 50+ langues). La recherche combine correspondance exacte (mots non-stopwords, accent-insensible) et similarité sémantique (distance cosine). La pertinence est calculée comme .
Quand un résumé LLM existe pour une session, c’est ce résumé qui est indexé dans ChromaDB (signal sémantique plus concentré). Sinon, le texte brut de la transcription est utilisé.
5. Post-traitement LLM
Trois scénarios de post-traitement sont disponibles via une API compatible OpenAI (Ollama, LM Studio) :
| Scénario | Description |
|---|---|
| Résumé | Synthèse en 2-4 phrases de la session |
| Liste de tâches | Extraction des actions mentionnées (format markdown) |
| Reformulation | Nettoyage des mots de remplissage, correction de grammaire |
Les prompts système s’adaptent automatiquement à la langue cible parmi les 13 supportées.
6. Stockage
Les données sont stockées localement dans SQLite (WAL mode, foreign keys) avec deux tables :
sessions: métadonnées (mode, langue, timestamps, durée, résumé LLM, nom de fichier)segments: texte transcrit avec timestamps de début/fin en millisecondes et score de confiance
Les migrations sont gérées via PRAGMA user_version. L’ensemble des données (base SQLite et index ChromaDB) est regroupé dans un dossier ./data/.
7. Défis techniques
CUDA sous Windows
CTranslate2, le moteur derrière faster-whisper, a besoin des librairies cuBLAS pour l’accélération GPU. Sous Windows, ces DLL sont installées par pip dans des sous-dossiers de site-packages/nvidia/*/bin/, un chemin que le système ne trouve pas automatiquement. Un scan récursif au démarrage via os.add_dll_directory() ajoute chaque dossier bin/ des packages NVIDIA.
ChromaDB synchrone dans un backend async
ChromaDB étant une librairie synchrone, chaque appel est wrappé dans asyncio.run_in_executor() pour éviter de bloquer la boucle d’événements du backend FastAPI.
Pont REST-WebSocket pour l’upload
L’upload de fichier suit un flow en deux temps : un POST REST crée la session et sauvegarde le fichier temporaire, puis le client se connecte en WebSocket pour recevoir la progression. Un registre en mémoire (dictionnaire avec TTL de 10 minutes) fait le pont entre les deux étapes.
8. Stack technique
| Couche | Technologies |
|---|---|
| Shell desktop | Tauri v2 (Rust), raccourcis globaux, system tray, injection texte (enigo + arboard) |
| Frontend | React 19, TypeScript 5.9, Vite 7, Tailwind CSS v4, shadcn/ui, Radix UI |
| Backend | Python 3.13, FastAPI, uvicorn, WebSocket |
| Transcription | faster-whisper (CTranslate2), Silero VAD, 6 modèles (tiny à large-v3-turbo) |
| Stockage | SQLite (aiosqlite, WAL mode), ChromaDB (cosine, embeddings 384-dim) |
| LLM | Client AsyncOpenAI compatible Ollama / LM Studio |
| Audio | sounddevice (PortAudio), 16kHz mono, 9 formats fichier via ffmpeg natif |
Ces projets pourraient vous intéresser

Rédaction de projets motivés
Assistant d'écriture Parcoursup basé sur CamemBERT pour structurer les lettres.

Exploration d'un Pipeline RAG
Benchmark d'un pipeline RAG et assemblage de l'outil dans un chat Chainlit.