
Outil d'aide à la rédaction de projets motivés Parcoursup, s'appuyant sur un modèle CamemBERT fine-tuné pour identifier et structurer les différentes parties d'une lettre de motivation. Le système intègre également un serveur de correction orthographique basé sur LanguageTool.
1. Collecte des données
La qualité de la classification repose sur la pertinence des données, plusieurs sources ont donc été mobilisées :
- Lettres publiques : des exemples de projets motivés publiés sur des blogs, forums et sites associatifs ont été collectés après accord.
- Corpus existants : des jeux de données open‑source ont été vérifiés pour s’assurer qu’ils correspondaient au format Parcoursup.
Au total, 320 lettres ont été conservées. Chaque document a été enregistré sous forme de texte brut puis stocké dans un tableau avec un identifiant unique.
2. Traitement des données
Le nettoyage et la préparation du corpus comportent plusieurs étapes :
- Normalisation : suppression des accents ou homogénéisation (par exemple, « Étudiant » → « étudiant »), élimination des caractères spéciaux et espaces multiples.
- Annotation manuelle : chaque phrase est assignée à l’une des sections (Introduction, Projet futur, Activités extra‑scolaires & Conclusion).
- Création du dataset : un fichier CSV est généré avec deux colonnes (
text,label). Le label est un entier de 0 à 3 correspondant à la section. - Division en ensembles : les données sont divisées en jeux d’entraînement (80 %) et de validation (20 %). Un échantillon est conservé pour tester le modèle final.
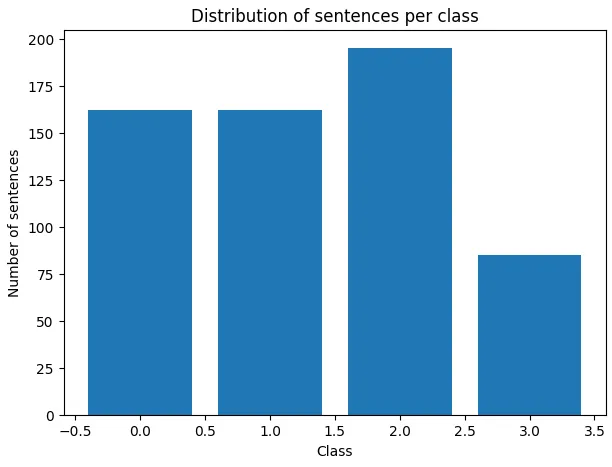
Figure 1 : Distribution du nombre de phrases par classes
Cette préparation garantit un corpus équilibré et représentatif des structures attendues dans un projet motivé Parcoursup, si l’on part du principe que l’échantillon est représentatif de lettres qualitatives.
3. Classification de phrases
Le cœur du système est un modèle CamemBERT (version de BERT adaptée au français) entraîné pour classer les phrases en quatre catégories. Les principales étapes de modélisation sont :
- Fine‑tuning : à partir du modèle pré‑entraîné
camembert-base, l’architecture est ajustée avec une couche de sortie de taille 4. Le jeu d’entraînement est utilisé sur plusieurs epochs avec un optimiseur AdamW. - Évaluation : la performance est mesurée sur le jeu de validation via l’accuracy, le F1-score et la matrice de confusion. Le modèle final atteint une accuracy d’environ 93 %, montrant donc que la différence entre les sections est bien capturée.
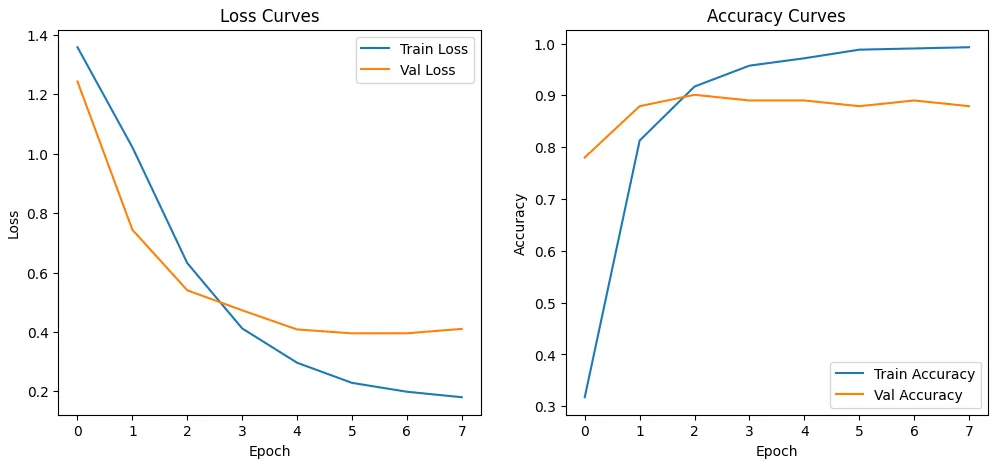
Figure 2 : Courbes d’entraînement Loss/Accuracy du jeu de données
- Persistance du modèle : le modèle et le tokenizer sont sauvegardés (fichiers
.ptet vocabulaire). Le chemin est spécifié viaMODEL_DIR/MODEL_PATH.
En production, le modèle est chargé une seule fois et mis en cache afin de minimiser la latence des requêtes.
4. Autres métriques
a) Lisibilité (Score Flesch)
On calcule le nombre de phrases n_sentences, de mots n_words et de syllabes n_syll (après normalisation et segmentation) puis le score de lisibilité :
b) Richesse lexicale (TTR lissée)
On calcule le Type-Token Ratio avec un lissage pour éviter de sur-évaluer les textes très courts :
- facteur de lissage :
- TTR lissée :
c) Connecteurs logiques
Deux indicateurs sont extraits à partir d’une liste de marqueurs regroupés par type :
- Couverture des connecteurs : nombre de types détectés
n_types, liste des types manquants, et détail des marqueurs présents par type (détection via regex avec bornes de mots, insensible à la casse). - Compte total : somme des occurrences de tous les marqueurs détectés.
d) Redondance lexicale
On mesure la répétition :
- Top mots : fréquences sur les mots en minuscules hors stopwords ;
- Top bigrammes : bigrammes consécutifs, en excluant ceux dont les deux mots sont des stopwords.
Les deux listes sont renvoyées avec leurs fréquences (paramètre top par défaut à 3).
e) Statistiques de référence (benchmarks)
Des moyennes et écarts-types empiriques servent à situer un texte relativement à un corpus interne :
-
asl_mean,asl_std(longueur moyenne de phrase) ; -
ttr_mean,ttr_std(richesse lexicale) ; -
flesch_mean,flesch_std(lisibilité).Ces valeurs alimentent le calcul de percentiles en aval du pipeline (pour un positionnement relatif des textes).
Remarques d’implémentation : les fonctions s’appuient sur des utilitaires communs (normalize_text, split_sentences, tokenize_words, count_syllables_fr, load_connectors, char_counts) et un dictionnaire de stopwords français.
5. Architecture
a) Backend
L’API FastAPI est conçue autour de trois routers :
-
/health: route de supervision qui retourne un objet{"status": "ok"}. Elle permet aux services d’orchestration de vérifier quel’instance est opérationnelle.
-
/analyze: route principale prenant un JSON{ "text": "..." }. Elle appelle successivement :- la fonction de correction grammaticale (LanguageTool) ;
- les calculs de métriques (score de Flesch, ratio type/token, connecteurs logiques, redondance) ;
- la fonction de notation qui combine ces métriques et pénalités pour produire une note sur 20 ;
- la classification des sections, si demandée. Le JSON retourné contient le texte corrigé, les positions des erreurs, les scores, les suggestions et la structure estimée.
-
/structure: prend un texte et retourne les phrases et leur étiquette de section ainsi que la liste des sections manquantes. Cette route est plus légère et peut être utilisée séparément pour guider l’utilisateur dans la construction de sa lettre.
Les services sont importés depuis backend/services/ ; ils utilisent transformers pour charger CamemBERT, language_tool_python pour les corrections et des fonctions maison pour les métriques. La configuration (core/config.py) centralise les paramètres (chemins, CORS, etc.).
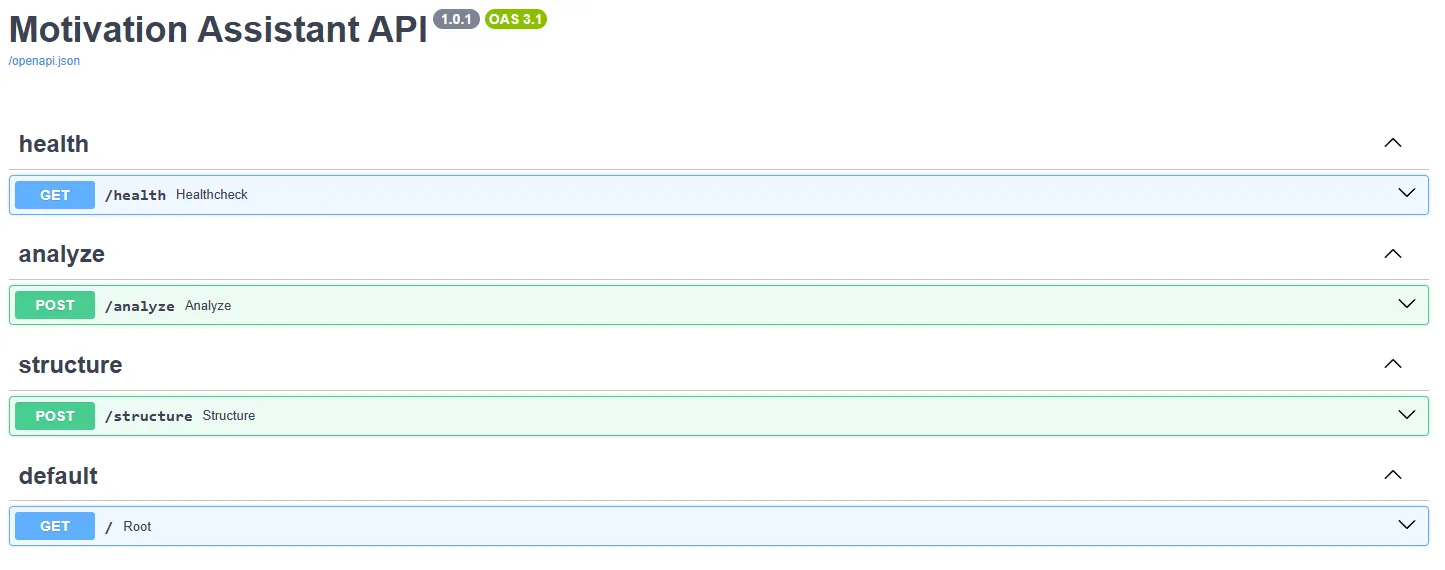
Figure 3 : Documentation des endpoints de l’API
b) Points d’attention
Quelques éléments nécessitent une vigilance particulière :
- Serveur LanguageTool : il doit être disponible pour que la route
/analyzefonctionne. Prévoir un mécanisme de bascule ou un cache si le service est indisponible. - Qualité des données : le biais dans les annotations peut influencer la classification. Continuer à enrichir le corpus et à valider les étiquetages est recommandé.
c) Frontend
L’interface web est développée avec React et orchestrée via Vite.
Elle propose :
- Un champ de saisie permettant de coller ou d’écrire sa lettre.
- Un bouton d’envoi qui appelle
/analyzeet affiche les résultats. - Des composants graphiques pour visualiser les sections (avec codes couleur), les erreurs grammaticales soulignées et les scores de lisibilité sous forme de barres ou de jauges.
L’architecture suit le modèle composant/context de React : des hooks gèrent l’état de la lettre et des résultats, tandis que des composants spécialisés s’occupent de l’affichage. Les appels à l’API sont centralisés dans frontend/api/ pour faciliter leur modification.
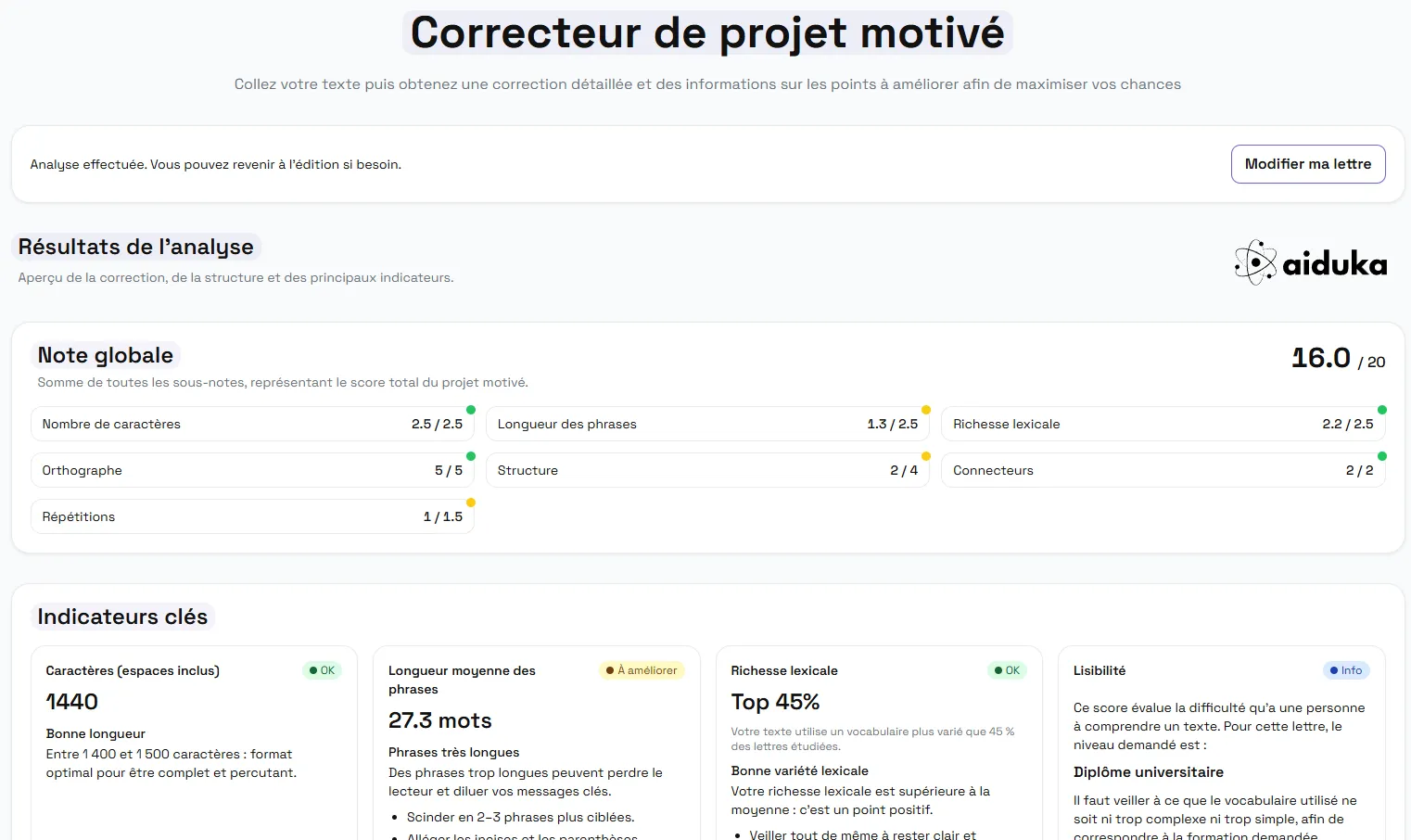
Figure 4 : Interface graphique de la page d’évaluation
d) Mise en ligne
Hébergement complet du backend et frontend sur Railway.
Figure 5 : Infrastructure Railway
Les étapes importantes sont :
- Construire et pousser une image Docker du backend contenant le modèle CamemBERT. Exposer le port
8000et veiller à chargerlanguagetool-server.jarou à pointer vers un service externe. - Charger le modèle et le mettre en cache pour la rapidité des futurs appels.
Ces projets pourraient vous intéresser

OpenWhisper
Transcrire la voix en texte en temps réel, 100% en local, via faster-whisper et Tauri.

Exploration d'un Pipeline RAG
Benchmark d'un pipeline RAG et assemblage de l'outil dans un chat Chainlit.