
Writing assistant for Parcoursup motivation letters, using a fine-tuned CamemBERT model to identify and structure the different sections of a motivation letter. The system also includes a spell-checking server based on LanguageTool.
1. Data Collection
Classification quality relies on data relevance, so several sources were mobilized:
- Public letters: examples of motivated projects published on blogs, forums, and association websites were collected after agreement.
- Existing corpora: open-source datasets were verified to ensure they matched the Parcoursup format.
In total, 320 letters were kept. Each document was saved as plain text and stored in a table with a unique identifier.
2. Data Processing
Corpus cleaning and preparation include several steps:
- Normalization: accent removal or homogenization (e.g., “Student” → “student”), elimination of special characters and multiple spaces.
- Manual annotation: each sentence is assigned to one of the sections (Introduction, Future Project, Extra-curricular Activities & Conclusion).
- Dataset creation: a CSV file is generated with two columns (
text,label). The label is an integer from 0 to 3 corresponding to the section. - Split into sets: data is divided into training (80%) and validation (20%) sets. A sample is kept to test the final model.
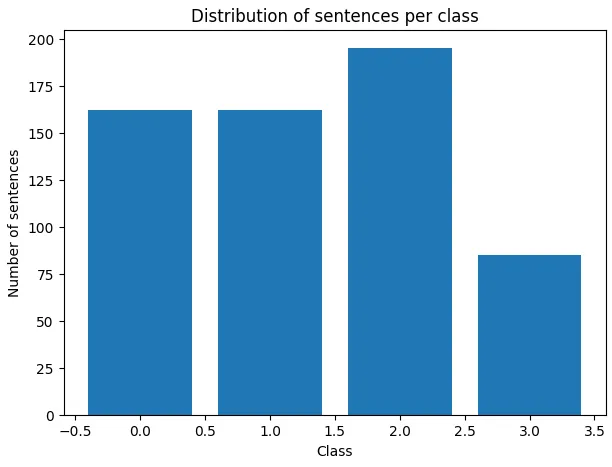
Figure 1: Distribution of Sentences per Class
This preparation ensures a balanced and representative corpus of expected structures in a Parcoursup motivation letter, assuming the sample is representative of quality letters.
3. Sentence Classification
The core of the system is a CamemBERT model (French-adapted BERT version) trained to classify sentences into four categories. The main modeling steps are:
- Fine-tuning: from the pre-trained
camembert-basemodel, the architecture is adjusted with an output layer of size 4. The training set is used over several epochs with an AdamW optimizer. - Evaluation: performance is measured on the validation set via accuracy, F1-score, and confusion matrix. The final model achieves an accuracy of about 93%, showing that the difference between sections is well captured.
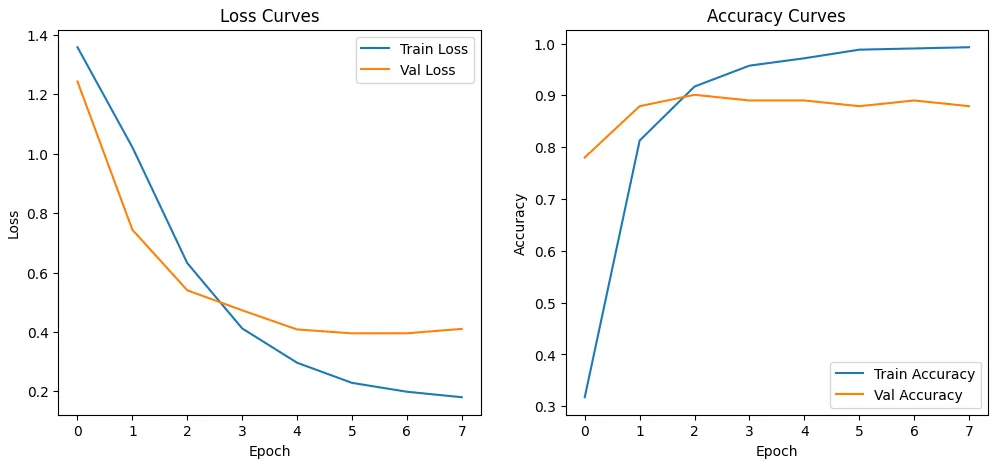
Figure 2: Training Loss/Accuracy Curves
- Model persistence: the model and tokenizer are saved (
.ptfiles and vocabulary). The path is specified viaMODEL_DIR/MODEL_PATH.
In production, the model is loaded once and cached to minimize request latency.
4. Other Metrics
a) Readability (Flesch Score)
We calculate the number of sentences n_sentences, words n_words, and syllables n_syll (after normalization and segmentation) then the readability score:
b) Lexical Richness (Smoothed TTR)
We calculate the Type-Token Ratio with smoothing to avoid overvaluing very short texts:
- smoothing factor:
- smoothed TTR:
c) Logical Connectors
Two indicators are extracted from a list of markers grouped by type:
- Connector coverage: number of detected types
n_types, list of missing types, and detail of markers present by type (detection via regex with word boundaries, case-insensitive). - Total count: sum of occurrences of all detected markers.
d) Lexical Redundancy
We measure repetition:
- Top words: frequencies on lowercase words excluding stopwords;
- Top bigrams: consecutive bigrams, excluding those where both words are stopwords.
Both lists are returned with their frequencies (default top parameter is 3).
e) Reference Statistics (benchmarks)
Empirical means and standard deviations serve to position a text relative to an internal corpus:
-
asl_mean,asl_std(average sentence length); -
ttr_mean,ttr_std(lexical richness); -
flesch_mean,flesch_std(readability).These values feed into percentile calculation downstream of the pipeline (for relative text positioning).
Implementation notes: functions rely on common utilities (normalize_text, split_sentences, tokenize_words, count_syllables_fr, load_connectors, char_counts) and a French stopwords dictionary.
5. Architecture
a) Backend
The FastAPI API is built around three routers:
-
/health: supervision route returning a{"status": "ok"}object. It allows orchestration services to verify thatthe instance is operational.
-
/analyze: main route taking a JSON{ "text": "..." }. It calls successively:- the grammatical correction function (LanguageTool);
- metric calculations (Flesch score, type/token ratio, logical connectors, redundancy);
- the scoring function that combines these metrics and penalties to produce a grade out of 20;
- section classification, if requested. The returned JSON contains the corrected text, error positions, scores, suggestions, and estimated structure.
-
/structure: takes a text and returns sentences with their section labels and the list of missing sections. This route is lighter and can be used separately to guide the user in constructing their letter.
Services are imported from backend/services/; they use transformers to load CamemBERT, language_tool_python for corrections, and custom functions for metrics. Configuration (core/config.py) centralizes parameters (paths, CORS, etc.).
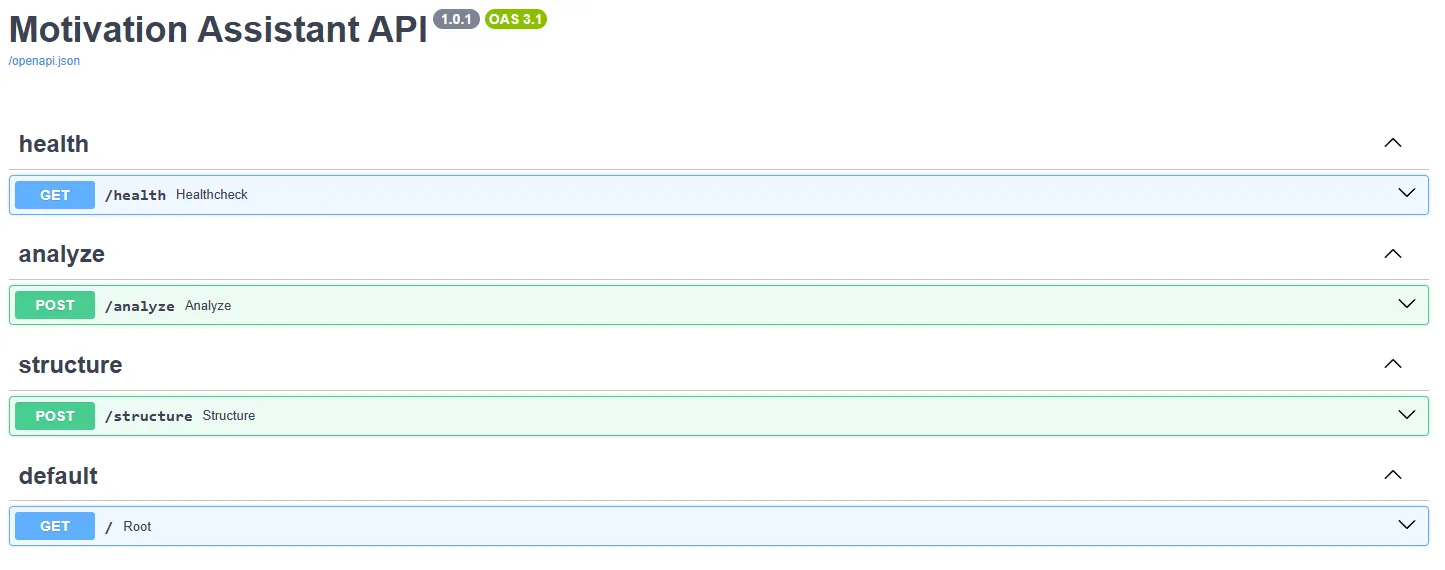
Figure 3: API Endpoints Documentation
b) Attention Points
Some elements require particular vigilance:
- LanguageTool server: it must be available for the
/analyzeroute to work. Plan a fallback mechanism or cache if the service is unavailable. - Data quality: bias in annotations can influence classification. Continuing to enrich the corpus and validate labeling is recommended.
c) Frontend
The web interface is developed with React and orchestrated via Vite.
It offers:
- An input field allowing pasting or writing the letter.
- A submit button that calls
/analyzeand displays results. - Graphical components to visualize sections (with color codes), underlined grammatical errors, and readability scores as bars or gauges.
The architecture follows React’s component/context model: hooks manage letter and result state, while specialized components handle display. API calls are centralized in frontend/api/ for easy modification.
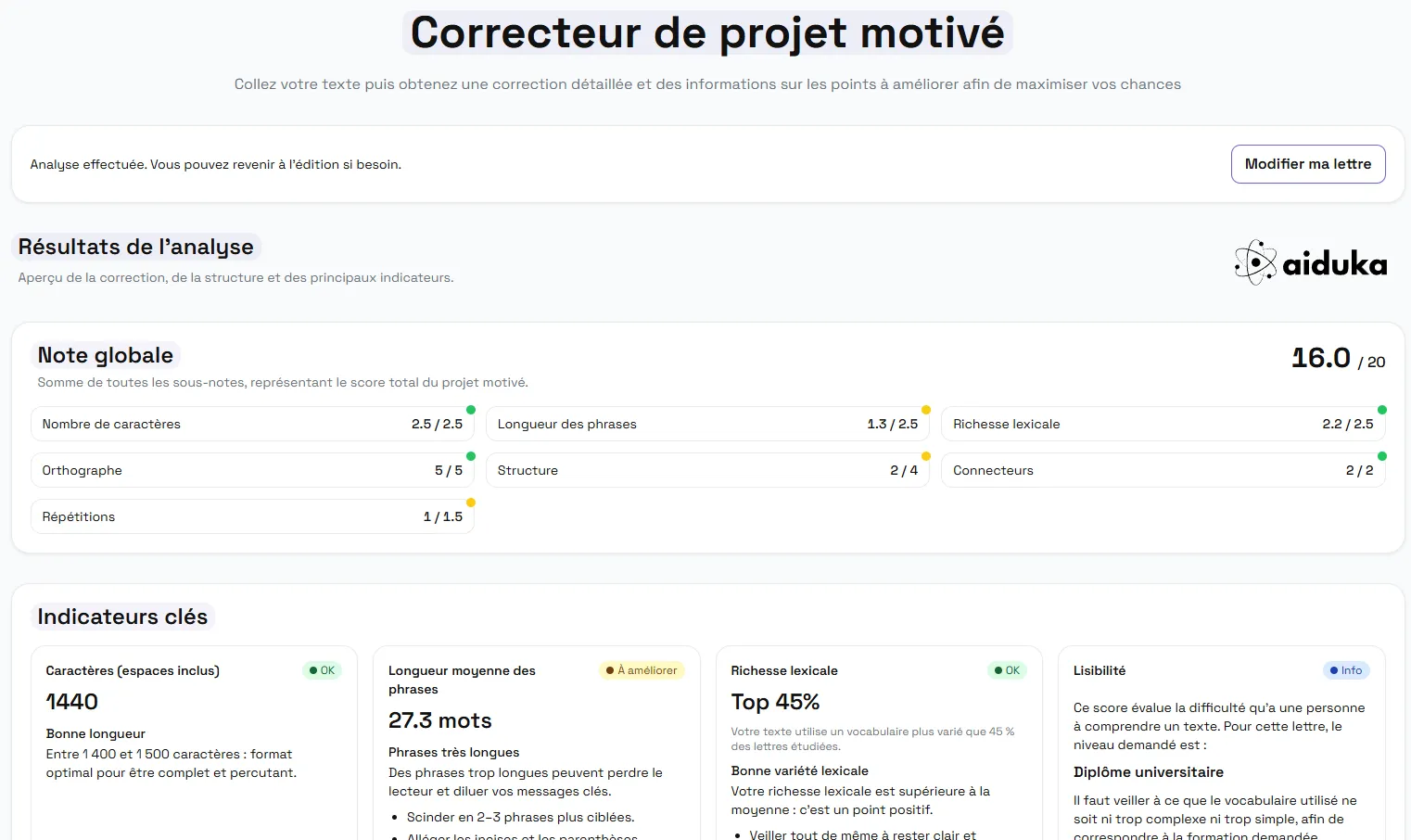
Figure 4: Evaluation Page Graphical Interface
d) Deployment
Complete backend and frontend hosting on Railway.
Figure 5: Railway Infrastructure
The important steps are:
- Build and push a Docker image of the backend containing the CamemBERT model. Expose port
8000and ensurelanguagetool-server.jaris loaded or point to an external service. - Load the model and cache it for speed of future calls.
These projects might interest you

OpenWhisper
Transcribe speech to text in real time, fully local, using faster-whisper and Tauri.

Exploring a RAG Pipeline
RAG pipeline benchmark and assembly of the tool into a Chainlit chat.