
Tool for estimating admission chances on Parcoursup, based on open data and explainable statistical modeling. The application combines a FastAPI backend and a React interface to provide an interactive and transparent experience.
1. Data Collection
a) Sources and Input Files
- Parcoursup Open Data – Statistics:
fr-esr-parcoursup.csvNumbers, honors mentions, rank of last accepted, distribution by baccalaureate, scholarship holders, etc. - Training Cartography:
fr-esr-cartographie_formations_parcoursup.csvMetadata (institution type, apprenticeship, boarding, geolocation, links). - Specialties (General Baccalaureate Holders):
fr-esr-parcoursup-enseignements-de-specialite-bacheliers-generaux.csvSpecialty pairs and admitted numbers. - Geographical Supplements:
departements-france.csvDepartment code normalization.
Geolocation fields are kept for display/diagnostic purposes, with no direct effect on the model (except for academic aggregations).
b) Enrichments through Scraping
- Parcoursup Sheets (Training Programs)
Retrieval: presentation, expectations (in % when available), baccalaureate distribution, milestones (candidates/admitted/admitted), tips,
competitiondetection. - “Competition” Consolidation
competition_labellabeling and, if available,dossier_coeff/competition_coeffcoefficients. - High School Sheets (L’Étudiant) Five “key figures” metrics (success rate, honors mentions, number of students, final year enrollment, grade/20) with anti-blocking strategies (retries, throttling, UA rotation).
2. Data Processing
Goal: produce “model-ready” tables through schema alignments, typing, imputations, and derived indicators.
a) Cleaning and Merging — Training Programs
-
Derived Indicators
- Average by honors mentions (weights 11/13/15/17/19).
- Distance to scale [8, 20] and proxy dispersion (from honors distribution).
- Gender bias and scholarship bias , bounded/normalized.
- Selectivity in (with filling if needed).
-
2025 Cartography & Geography
Normalizations (apprenticeship → boolean, categorized boarding, types), renaming, department and city completion, join with department table.
-
Training Family Harmonization
Exhaustive
formation_type → formationmapping (e.g., “Selective License” → “License – STS”), coverage checks. -
Adding “Competition”
Adding
competitionanddossier_coeff,competition_coefffrom training programs present in certain competitions (Sésame, Accès, Geipi-Polytech, Avenir, Advance, Puissance Alpha, IEP-Sciences Po).
b) Specialties
-
Open Data
Filtering by year, pairs (doublets) → stable IDs (1..13), calculation of
admitted_specialty_shareper training program, intra-training ranking. -
Scraping
combinationcolumns →doublet_iinid1,id2format (viaspecialite2id).
c) High Schools
-
Robust Scraping
Incremental enrichment, typing, anti-blocking.
-
Feature Engineering & Multiplier
Decimals (success, honors), metric ,
infosindicator.Bounded transformation into via z-score → CDF → exponential; if
infos=0then .
Figure 1: Data Processing Pipeline
3. Establishing Metrics
Idea: convert each factor into a multiplier centered at 1, bounded to avoid extremes, then aggregate.
-
Demographics (bounded, symmetric)
with , , (~±2.5%).
-
General Grades (calibrated to cohort)
Let be the candidate’s average, those of the training program (from honors).
.
with
-
Specialty Grades (consistency)
truncated to .
-
Baccalaureate Type (representativeness)
For non-general baccalaureates: floor according to observed share .
-
Specialty Pair (adequacy/rarity)
With the share of admitted students with the pair and the average of the most frequent pairs (often ), set .
-
High School of Origin (academic context)
Aggregated score → , .
with , , , .
If
infos=0then .
4. Chosen Model
a) Aggregated Score
The global score for a training program is:
All are capped (bounds) to remain stable and interpretable.
b) Conversion to Calibrated Percentile
We assume is centered around 1 and choose such that the 97.5th percentile corresponds to:
, , .
The displayed value is .
c) Three-Level Decision
- Rejected if
- Waiting List if
- Accepted if
Simple thresholds adjustable by training/year for local calibration refinement.
d) Explainability
In addition to , the service returns the main factor (dominant component) to explain the result (grades, doublet, baccalaureate type, high school, etc.). Demographic effects are bounded and symmetric.
e) “Competition” Case (optional)
If competition = 1, a post-dossier weighting is applied from a user competition grade and dossier_coeff/competition_coeff coefficients (when available).
Example: → Accepted.
5. Backend Architecture
- Framework: FastAPI (
main.py) Config viacore/config.py, middlewares (CORS,UserIdMiddleware), dependenciescore/deps.py. - Search Infrastructure: Integration of Typesense, a typo-tolerant and fast search engine, for instant indexing and querying of training programs and institutions.
- Routers:
routers/simulate.py: Simulation API (modelProfile, callcompute_admission).routers/formations.py: Training search & stats (BM25, geo filters, distributions).routers/profiles.py: Profile CRUD (Profile,Wish).routers/motive.py: Letter generation and sending (OpenAI API + Brevo).routers/lycees.py: High school search (department/type weights).routers/share.py: Sending results by email (HTML rendering, Brevo).
- Database & ORM:
db/database.py(SQLAlchemy / SQLite),models/profile.py.
Figure 2: API Endpoints Documentation
6. Backend Attention Points
- Mailing:
/share/simulation→ HTML rendering via_render_motive_body_html, sending via Brevo (keys in.env.local:BREVO_API_KEY,BREVO_EMAIL_SENDER). - Motivation Letter:
/motive/generate(generation),/motive/email(sending). - Search Engine: Migration to Typesense enabling synonym management, typo tolerance, and relevant result sorting.
- Academic Filtering:
frontend/constants/acad_map.json(department → academy/territory).
7. Frontend Architecture
- Stack: React (Vite). Entry
main.jsx, appApp.jsx. - Advanced Features:
- Dynamic Theming: Intelligent system detecting origin URL to automatically adapt branding (logo, color palette, links) and enable multi-site white-label deployment.
- Sharing and Public Profiles: Creation of public profile pages accessible via unique URL, allowing vendors to easily access students’ simulations and wish lists.
- Training Comparator: Interactive tool allowing side-by-side comparison of multiple training programs on key criteria (selectivity, career prospects, expectations).
Figure 3: Accessible Profile Sheet
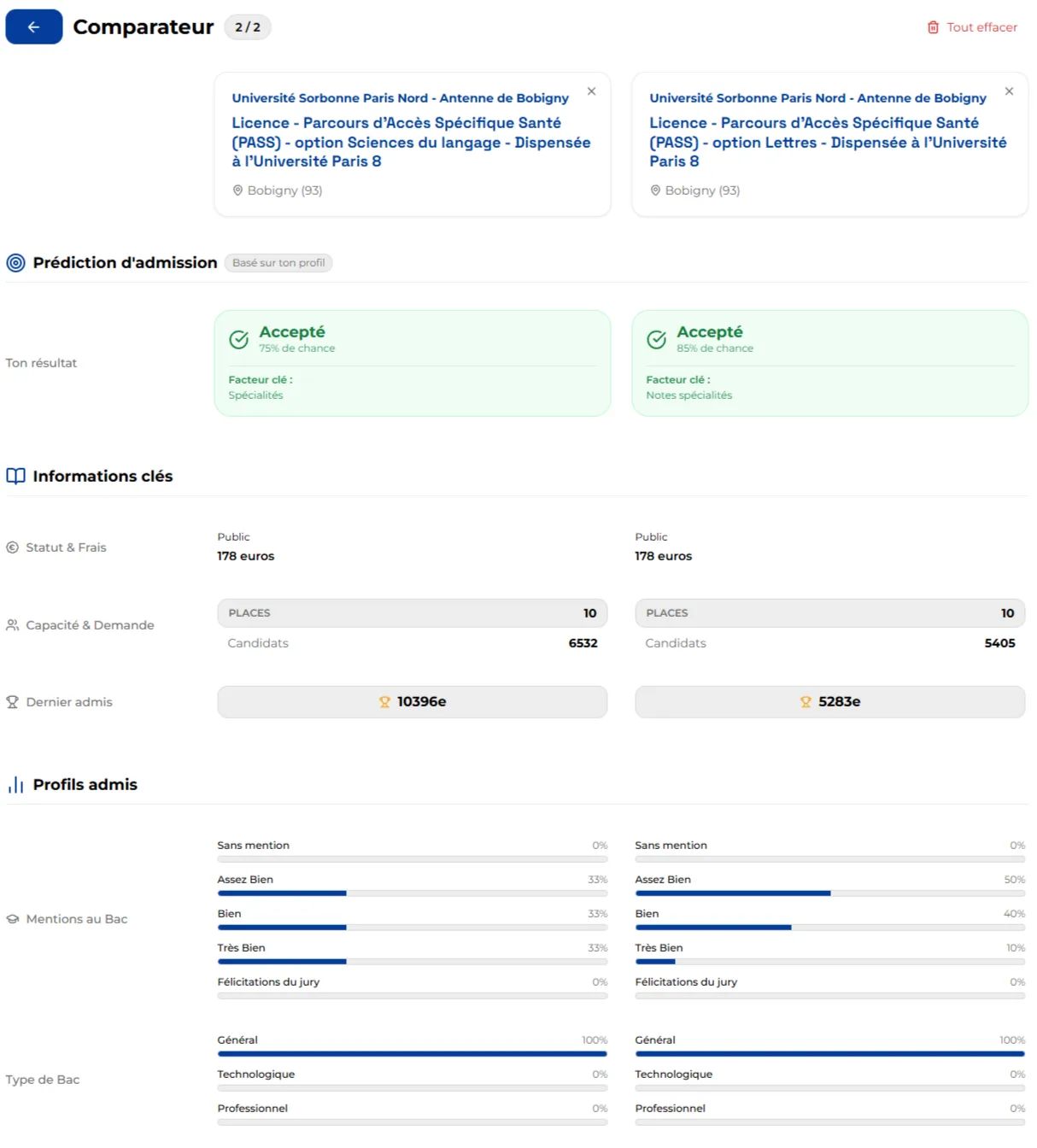
Figure 4: Training Program Comparator
- Key Folders:
api/api.js: endpoint calls (simulation, training programs, profiles, motivation, etc.).components/:details/,motivation/,registration/,search/.constants/:complete_form.json,concours.json,confidence_levels.json,factorExplains.js,thresholds.js.context/: global state, theme (styles/theme.css,utils/ThemeLogo.jsx).pages/: home, training programs, simulator, profile, letter.utils/: pagination, conversions, helpers.
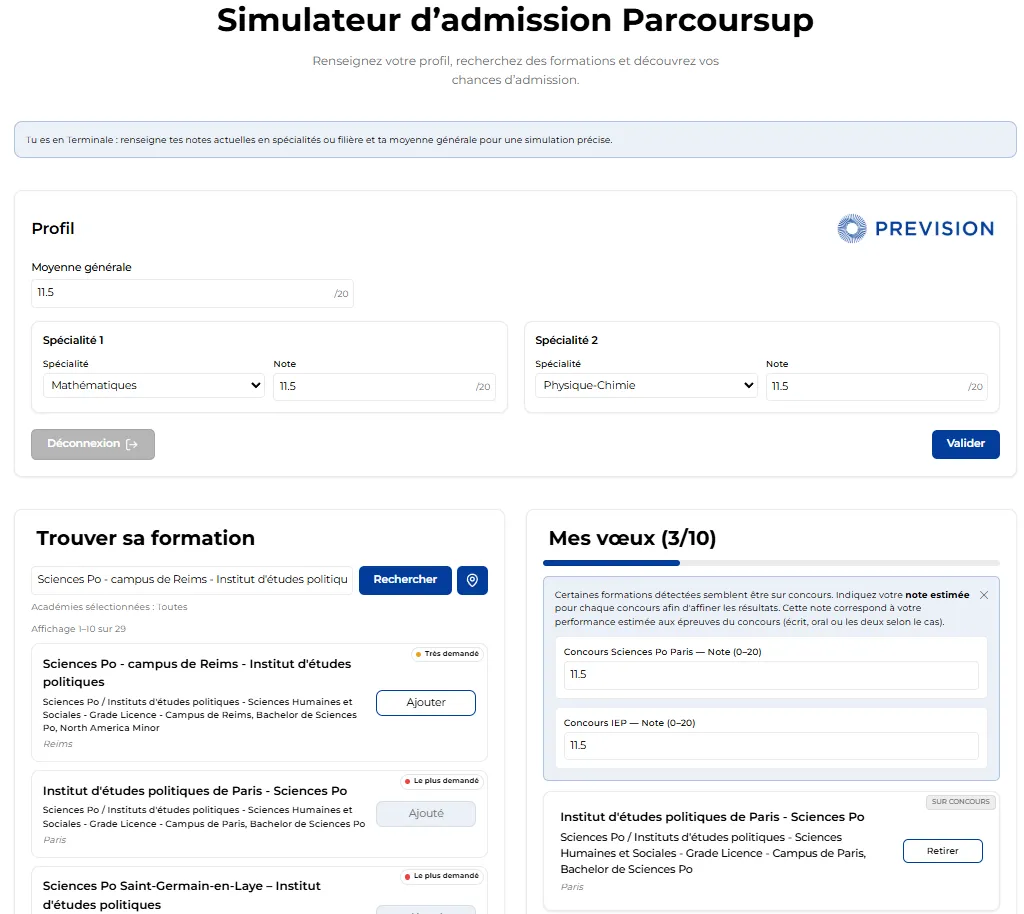
Figure 5: Search Page Graphical Interface
8. Deployment
a) Railway Hosting
Complete backend and frontend hosting with a connected PostgreSQL database and Typesense instance (Docker).
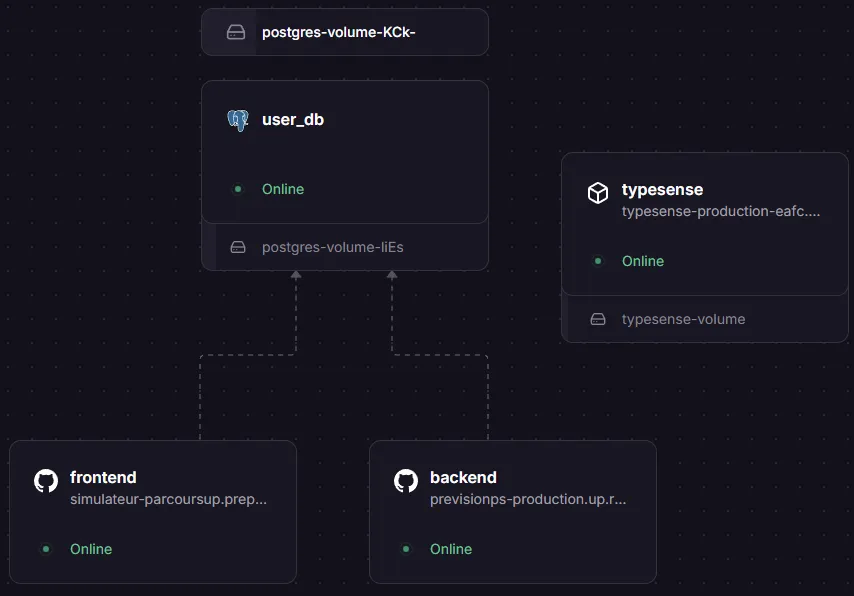
Figure 6: Railway Infrastructure
b) n8n Automation
- Trigger: Scheduled (Schedule Trigger) for periodic execution.
- Process: Daily synchronization of data (Profiles and Wishes) from the database to Google Sheets segmented by client.
- Purpose: Automatic feeding of tracking data and triggering sub-workflows for dashboard updates.
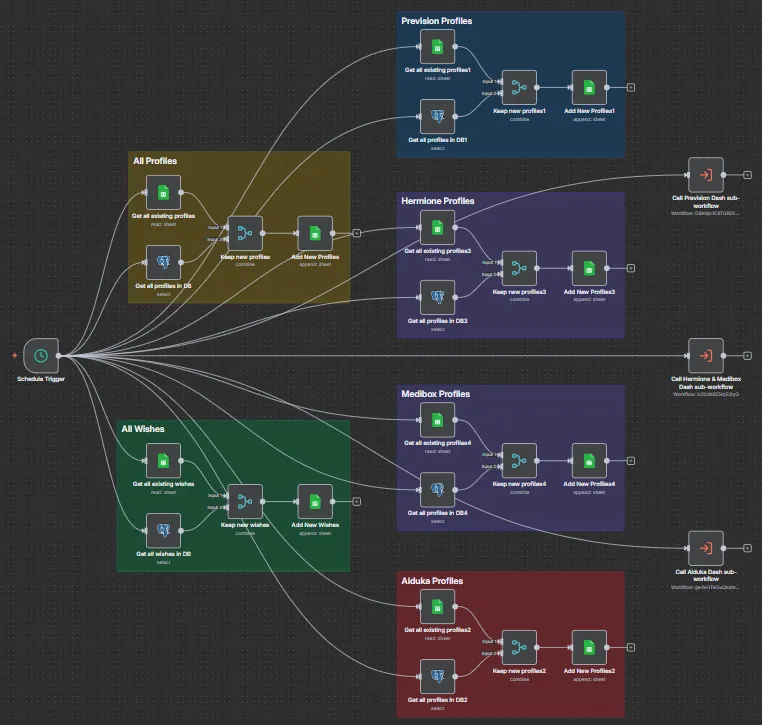
Figure 7: n8n Automation Workflow
These projects might interest you

Exploring a RAG Pipeline
RAG pipeline benchmark and assembly of the tool into a Chainlit chat.

MCP Data Science
102 data science tools driven by natural language via Anthropic's MCP protocol.