
Outil d'estimation des chances d'admission sur Parcoursup, basé sur les données ouvertes et une modélisation statistique explicable. L'application combine une API FastAPI et une interface React pour offrir une expérience interactive et transparente.
1. Collecte des données
a) Sources et fichiers d’entrée
- Open data Parcoursup – statistiques :
fr-esr-parcoursup.csvEffectifs, mentions, rang du dernier appelé, répartition par bac, boursiers, etc. - Cartographie des formations :
fr-esr-cartographie_formations_parcoursup.csvMétadonnées (type d’établissement, apprentissage, internat, géolocalisation, liens). - Spécialités (bacheliers généraux) :
fr-esr-parcoursup-enseignements-de-specialite-bacheliers-generaux.csvDoublettes de spécialités et effectifs admis. - Compléments géo :
departements-france.csvNormalisation des codes départements.
Les champs de géolocalisation sont conservés à des fins d’affichage/diagnostic, sans effet direct dans le modèle (hors agrégations académiques).
b) Enrichissements par scraping
- Fiches Parcoursup (formations)
Récupération : présentation, attendus (en % quand disponible), répartition bac, jalons (candidats/admissibles/admis), conseils, détection
concours. - Consolidation “concours”
Étiquetage
concours_labelet, si disponibles, coefficientscoeff_dossier/coeff_concours. - Fiches lycées (L’Étudiant) Cinq métriques « chiffres-clés » (réussite, mentions, nb d’élèves, effectif terminale, note/20) avec stratégies anti-blocage (retries, throttling, UA rotation).
2. Traitement des données
But : produire des tables “modèle-prêtes” via alignements de schémas, typages, imputations et indicateurs dérivés.
a) Nettoyage et fusion — Formations
-
Indicateurs dérivés
- Moyenne par mentions (pondérations 11/13/15/17/19).
- Distance à l’échelle [8, 20] et dispersion proxy (depuis la distribution des mentions).
- Biais genre et boursiers , bornés/normalisés.
- Sélectivité dans (avec comblement si besoin).
-
Cartographie 2025 & géo
Normalisations (apprentissage → booléen, internat catégorisé, types), renommages, complétion des départements et villes, jointure avec table des départements.
-
Harmonisation familles de formation
Mapping exhaustif
formation_type → formation(ex. « Licence sélective » → « Licence – STS »), contrôles de couverture. -
Ajout “concours”
Ajout de
concoursetcoeff_dossier,coeff_concoursà partir de formations présentes dans certains concours (Sésame, Accès, Geipi-Polytech, Avenir, Advance, Puissance Alpha, IEP-Sciences Po).
b) Spécialités
-
Open data
Filtrage par millésime, couples (doublettes) → IDs stables (1..13), calcul de
part_spe_admispar formation, ranking intra-formation. -
Scraping
Colonnes
combination→doublette_iau formatid1,id2(viaspecialite2id).
c) Lycées
-
Scraping robuste
Enrichissement incrémental, typages, anti-blocage.
-
Feature engineering & multiplicateur
Décimaux (réussite, mentions), métrique , indicateur
infos.Transformation bornée en via z-score → CDF → exponentielle ; si
infos=0alors .
Figure 1 : Pipeline de traitement des données
3. Établissement des métriques
Idée : convertir chaque facteur en multiplicateur centré en 1, borné pour éviter les extrêmes, puis agréger.
-
Démographie (bornée, symétrique)
avec , , (~±2,5 %).
-
Notes générales (calibrées à la cohorte)
Soit la moyenne du candidat, celles de la formation (depuis les mentions).
.
avec
-
Notes de spécialités (cohérence)
tronqué à .
-
Type de bac (représentativité)
Pour bacs non généraux : plancher selon la part observée .
-
Doublette de spécialités (adéquation/rareté)
Avec la part d’admis portant la doublette et la moyenne des doublettes les plus fréquentes (souvent ), poser .
-
Lycée d’origine (contexte académique)
Score agrégé → , .
avec , , , .
Si
infos=0alors .
4. Modélisation choisie
a) Score agrégé
Le score global pour une formation est :
Tous les sont plafonnés (bornes) pour rester stables et interprétables.
b) Conversion en percentile calibré
On suppose centré autour de 1 et on choisit tel que le 97,5e centile corresponde à :
, , .
La valeur affichée est .
c) Décision à trois niveaux
- Refusé si
- En attente si
- Accepté si
Seuils simples et ajustables par formation/millésime pour affiner la calibration locale.
d) Explicabilité
Outre , le service retourne le facteur principal (composante dominante) afin d’expliquer le résultat (notes, doublette, type de bac, lycée, etc.). Les effets démographiques sont bornés et symétriques.
e) Cas “concours” (optionnel)
Si concours = 1, une pondération post-dossier est appliquée à partir d’une note de concours utilisateur et coefficients coeff_dossier/coeff_concours (quand disponibles).
Exemple : → Accepté.
5. Architecture backend
- Framework : FastAPI (
main.py) Config viacore/config.py, middlewares (CORS,UserIdMiddleware), dépendancescore/deps.py. - Infrastructure de Recherche : Intégration de Typesense, un moteur de recherche tolérant aux fautes de frappe et rapide, pour l’indexation et l’interrogation instantanée des formations et établissements.
- Routeurs :
routers/simulate.py: API de simulation (modèleProfil, appelcompute_admission).routers/formations.py: recherche & stats formations (BM25, filtres géo, distributions).routers/profiles.py: CRUD profils (Profile,Voeu).routers/motive.py: génération et envoi de lettres (API OpenAI + Brevo).routers/lycees.py: recherche de lycées (pondérations département/type).routers/share.py: envoi des résultats par mail (rendu HTML, Brevo).
- Base & ORM :
db/database.py(SQLAlchemy / SQLite),models/profile.py.
Figure 2 : Documentation des endpoints de l’API
6. Points d’attention backend
- Mailing :
/share/simulation→ rendu HTML via_render_motive_body_html, envoi via Brevo (clés dans.env.local:BREVO_API_KEY,BREVO_EMAIL_SENDER). - Lettre de motivation :
/motive/generate(génération),/motive/email(envoi). - Moteur de Recherche : Migration vers Typesense permettant la gestion des synonymes, la tolérance aux fautes de frappe et un tri pertinent des résultats.
- Filtrage académique :
frontend/constants/acad_map.json(département → académie/territoire).
7. Architecture frontend
- Stack : React (Vite). Entrée
main.jsx, appApp.jsx. - Fonctionnalités avancées :
- Thématisation dynamique : Système intelligent détectant l’URL d’origine pour adapter automatiquement le branding (logo, palette de couleurs, liens) et permettre un déploiement multi-site en marque blanche.
- Partage et profils publics : Création de pages de profil publiques accessibles via URL unique, permettant aux vendeurs d’accéder facilement aux simulations et listes de vœux des élèves.
- Comparateur de formations : Outil interactif permettant de comparer côte à côte plusieurs formations sur des critères clés (sélectivité, débouchés, attendus).
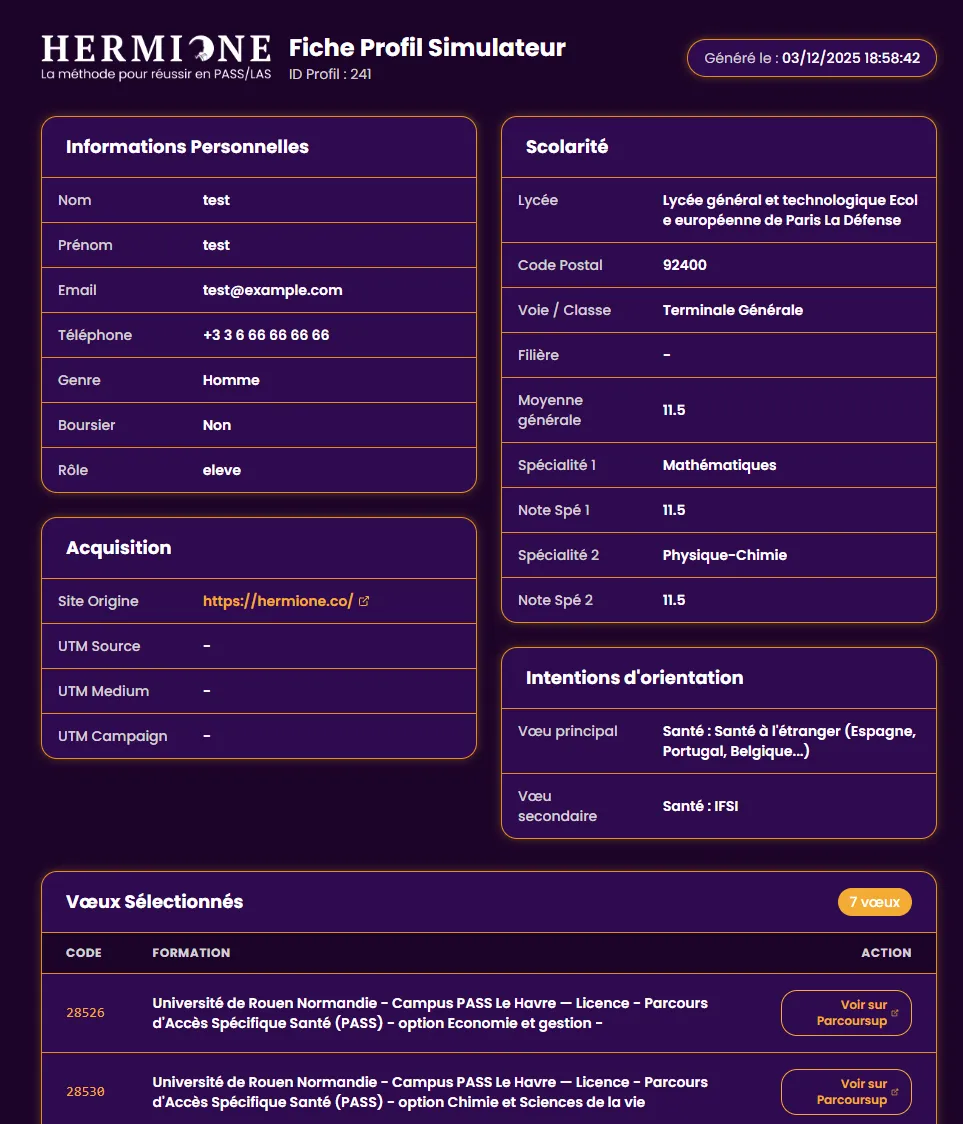
Figure 3 : Fiche profil accessible
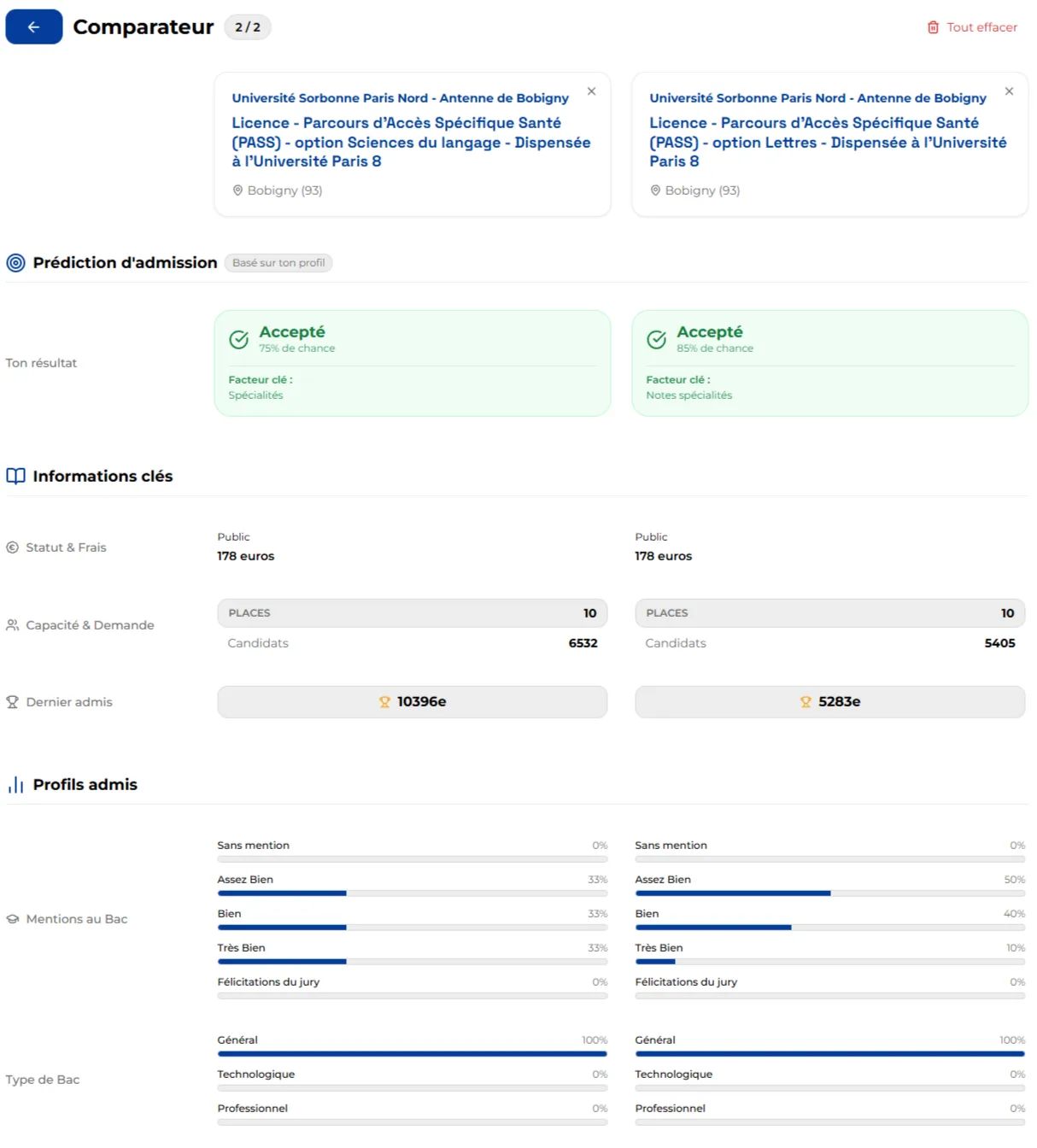
Figure 4 : Comparateur de formations
- Dossiers clés :
api/api.js: appels aux endpoints (simulation, formations, profiles, motive, etc.).components/:details/,motivation/,registration/,search/.constants/:complete_form.json,concours.json,confidence_levels.json,factorExplains.js,tresholds.js.context/: état global, thème (styles/theme.css,utils/ThemeLogo.jsx).pages/: accueil, formations, simulateur, profil, lettre.utils/: pagination, conversions, helpers.
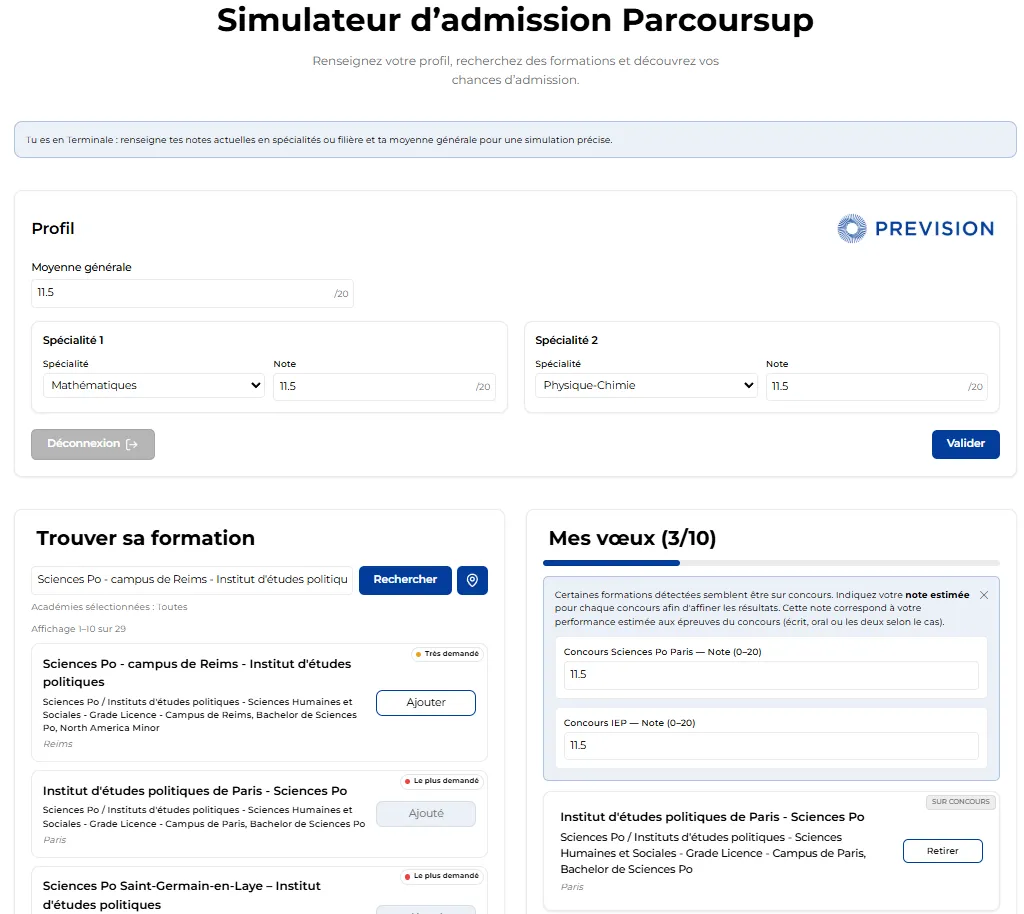
Figure 5 : Interface graphique de la page de recherche
8. Mise en ligne
a) Hébergement Railway
Hébergement complet du backend et frontend avec une base de données PostgreSQL connectés et instance Typesense (Docker).
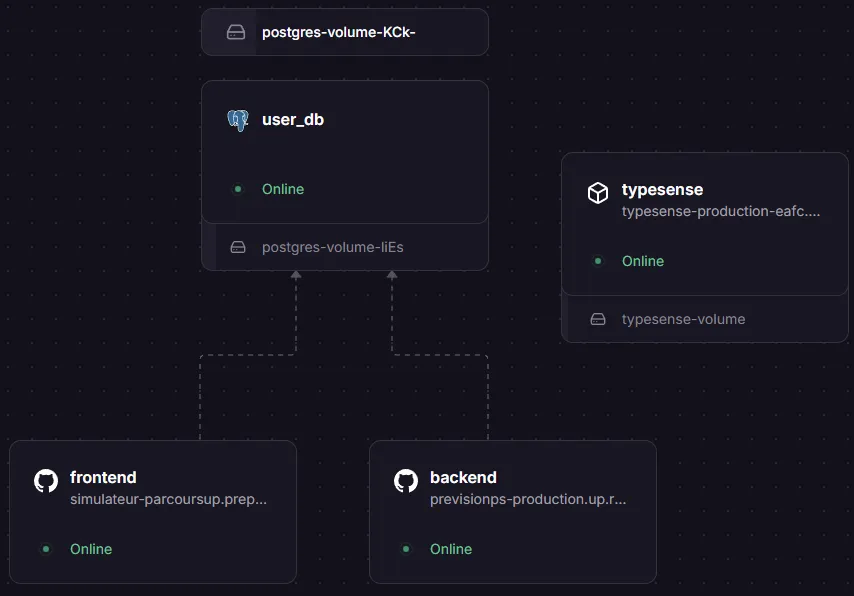
Figure 6 : Infrastructure Railway
b) Automatisation n8n
- Déclencheur : Planifié (Schedule Trigger) pour une exécution périodique.
- Processus : Synchronisation quotidienne des données (Profils et Vœux) depuis la base de données vers des Google Sheets segmentés par client.
- Finalité : Alimentation automatique des données de suivi et déclenchement de sous-workflows pour la mise à jour des tableaux de bord (Dashboards).
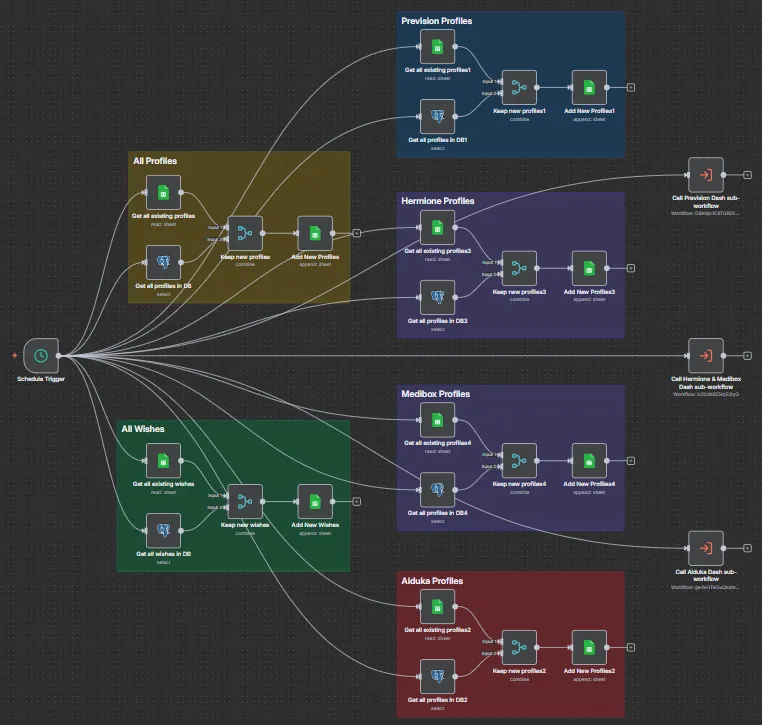
Figure 7 : Workflow automatisation n8n
Ces projets pourraient vous intéresser

Exploration d'un Pipeline RAG
Benchmark d'un pipeline RAG et assemblage de l'outil dans un chat Chainlit.

MCP Data Science
102 outils de data science pilotés en langage naturel via le protocole MCP d'Anthropic.